The artificial intelligence landscape is evolving at an unprecedented pace, with new models and advancements emerging almost daily. Among these, the recent release of DeepSeek R1-0528 has sent ripples across the industry, proving to be a surprising and powerful contender in the open-source AI arena. Initially perceived as a minor iteration, this new model is demonstrating performance that challenges the dominance of established giants like OpenAI and Google’s Gemini, setting the stage for an intriguing battle in the race for AI supremacy.
The Unprecedented Leap: DeepSeek R1-0528’s Stunning Performance
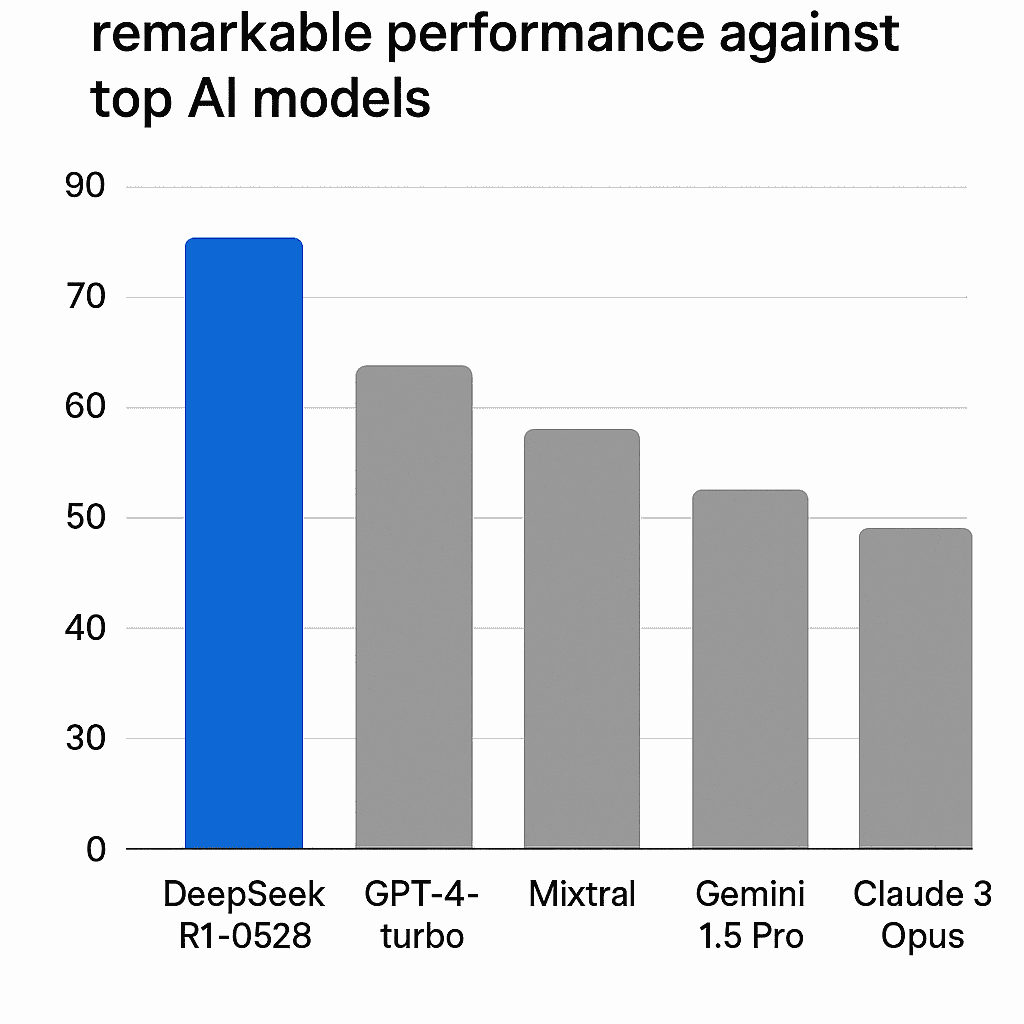
DeepSeek R1-0528 isn’t just an incremental update; it represents a significant jump in capability. According to the Artificial Intelligence Index, the model’s performance score surged from 60 (its older January 2025 version) to an impressive 68. This places DeepSeek R1-0528 squarely among the front-runners, neck and neck with leading closed-source models.
DeepSeek R1-0528 (May ’25) demonstrates remarkable performance against top AI models.
A closer look at specific benchmarks reveals its prowess:
Live Code Bench: DeepSeek R1-0528 is on par with OpenAI’s O3 (GPT-3 level performance).
AIME 2024 & 2025: While slightly behind O3, it impressively surpasses Gemini 2.5 Pro.
Across various other benchmarks posted by DeepSeek, including GPQA Diamond and Aider, the model consistently ranks near the top, often beating out Gemini 2.5 Pro in several key areas.
This level of performance from an open-source model is a game-changer. The AI community was largely anticipating DeepSeek R2, the next major model, but this update suggests that DeepSeek is already delivering top-tier capabilities, making high-performance AI more accessible than ever before.
Unraveling the Mystery: How DeepSeek R1-0528 Achieved Its Edge
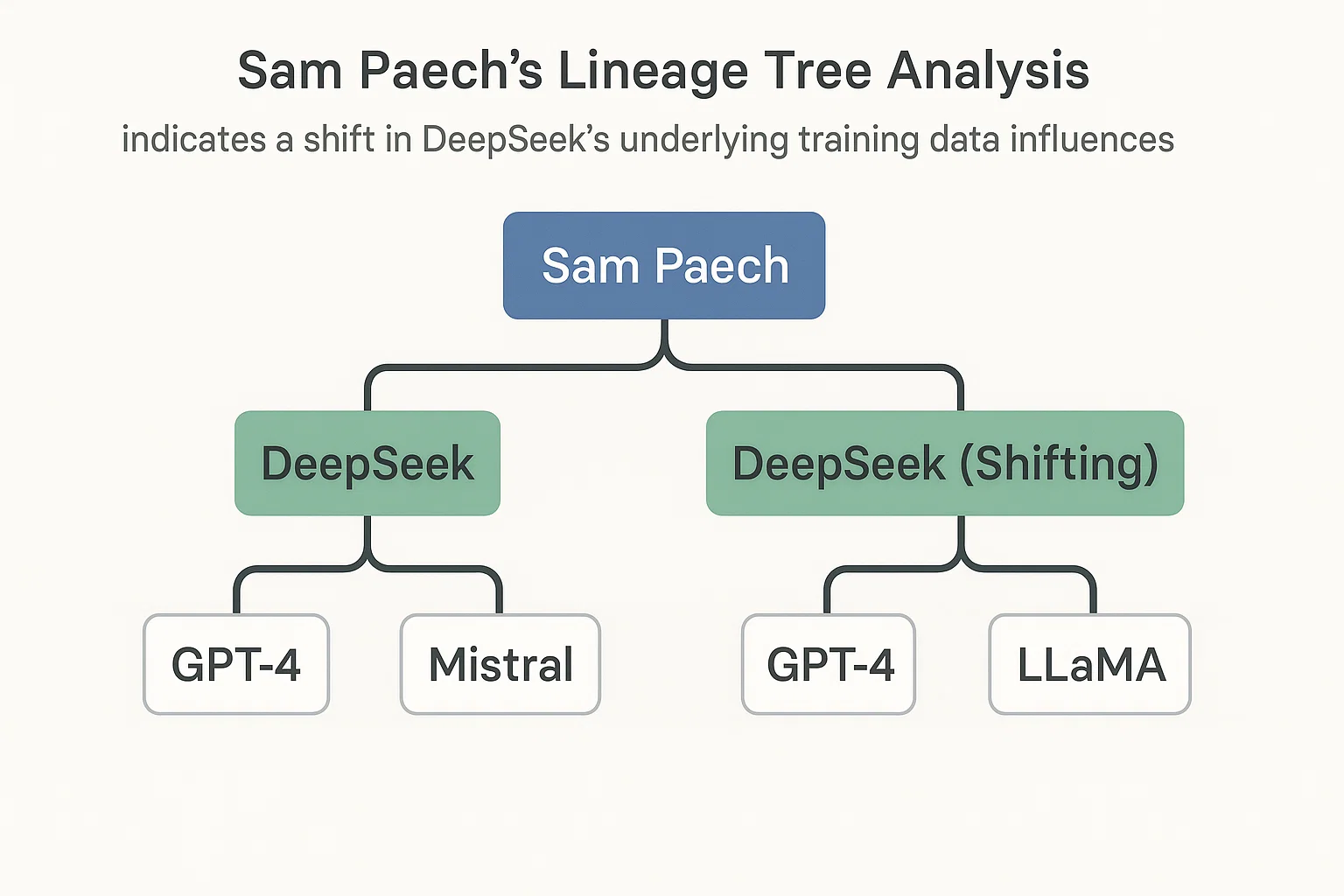
The burning question is: how did DeepSeek manage such a significant leap? Insights from AI researcher Sam Paech, who runs EQ-Bench (Emotional Intelligence Benchmarks for LLMs), offer a fascinating hypothesis. Paech’s work involves generating “slop profiles” for various AI models, analyzing their creative writing outputs for repetitive words and patterns (like how GPT models often “delve” into “tapestries”). He then uses bioinformatics tools to infer “lineage trees” based on these profiles, essentially tracing a model’s stylistic and behavioral heritage.
Sam Paech’s lineage tree analysis indicates a shift in DeepSeek’s underlying training data influences.
Paech’s analysis shows that the original DeepSeek R1 model clustered closely with OpenAI’s GPT technologies. However, the new DeepSeek R1-0528 model has shifted dramatically, now appearing very similar to Google’s Gemini family of models, specifically Gemini 2.5 Pro Experimental. This suggests a potential strategy: DeepSeek may have switched from training on synthetic outputs generated by OpenAI models to those generated by Gemini models. This practice, often referred to as “knowledge distillation” or “training on synthetic data,” allows developers to leverage the strengths and nuances of leading models to rapidly improve their own, even if the original training data is proprietary.
The Geopolitical Chessboard: DeepSeek R1-0528 and the Global AI Race
The emergence of powerful open-source models like DeepSeek R1-0528 has significant geopolitical implications. The video highlights a clear competitive narrative between the U.S. and China in AI development.
The U.S. Department of Energy explicitly states, “AI is the next Manhattan Project, and THE UNITED STATES WILL WIN.” This comparison to the WWII atomic bomb project underscores the national security and economic importance placed on AI.
Analyst Balaji Srinivasan previously predicted a “complete blitz of Chinese open-source AI models,” inferring that China aims to “take the profit out of AI software” by commoditizing it through AI-enabled hardware. The idea is to copy, optimize, and scale software, then disrupt Western originals with low prices, much like in manufacturing.
DeepSeek’s founder, Liang Wenfang, echoes this sentiment: “In the face of disruptive technologies, moats created by closed source are temporary. Even OpenAI’s closed source approach can’t prevent others from catching up. So we anchor our value in our team… an organization and culture capable of innovation. That’s our moat. We will not change to closed source.” This quote from Liang Wenfang (as featured in an AI Explained documentary) powerfully asserts DeepSeek’s commitment to open-source and its belief in the long-term viability of that approach.
Furthermore, the U.S. government is subtly (or not so subtly) subsidizing domestic AI research through legislative changes like “The One, Big Beautiful Bill,” which allows companies to fully deduct software development costs (including salaries) for domestic R&D expenses. This is a massive incentive for U.S. tech companies to invest heavily in AI development, without explicitly using the term “AI” in the bill itself.
DeepSeek R1-0528’s Price Advantage
Beyond performance, DeepSeek R1-0528 presents a compelling economic argument. Its API pricing is significantly lower than its closed-source counterparts:
The cost difference is stark. An open-source model matching or even exceeding the performance of leading proprietary models, offered at a fraction of the price, represents a massive disruption. It effectively removes a major revenue stream for companies relying solely on high-priced API access, forcing them to innovate beyond just raw model performance.
The Accelerating Pace: What’s Next for Open-Source AI?
The stakes in the AI race are rapidly ramping up. As Dr. Jim Fan from Nvidia points out, we are living in a timeline where a non-US company is keeping the original mission of OpenAI alive – truly open, frontier research that empowers all. While competition between nations and companies is intensifying, the open-source community continues to push the boundaries of what’s possible, often making breakthroughs accessible to everyone.
The increasing overlap between government interests and AI labs, coupled with initiatives to subsidize domestic AI development, suggests a future where AI progress is not just driven by a few tech giants, but becomes a national imperative. This dynamic will likely lead to even faster development cycles, more diverse applications, and potentially a more democratized AI ecosystem as open-source models like DeepSeek R1-0528 continue to challenge the status quo. The wheels are turning ever faster, and we are just getting started.
The recent joint statement from Microsoft and OpenAI has reaffirmed their long-term AI partnership, as reported by FutureTools News. This commitment to collaboration is expected to drive innovation in the field of artificial intelligence and shape the future of technology. The partnership between Microsoft and OpenAI has been instrumental in developing cutting-edge AI solutions, including the integration of OpenAI’s models with Microsoft’s Azure cloud platform.
Background of the Partnership
The partnership between Microsoft and OpenAI was formed with the goal of advancing the field of artificial intelligence and developing new technologies that can benefit society. The collaboration has led to significant breakthroughs in areas such as natural language processing and computer vision. The joint statement from Microsoft and OpenAI emphasizes their shared commitment to responsible AI development and the importance of ensuring that AI systems are aligned with human values.
Key Areas of Focus
The partnership between Microsoft and OpenAI is focused on several key areas, including the development of large language models and the integration of AI with other technologies such as GitHub and AWS. The goal is to create AI systems that can learn and improve over time, and that can be used to solve complex problems in areas such as healthcare and education. As stated by a Microsoft spokesperson,
The partnership between Microsoft and OpenAI is a key part of our strategy to advance the field of artificial intelligence and to develop new technologies that can benefit society. We are committed to working together to ensure that AI systems are developed and used in ways that are responsible and aligned with human values.
Future Directions
The joint statement from Microsoft and OpenAI also highlights their plans for future collaboration and innovation. The partners are expected to continue working together to develop new AI technologies and to explore new applications for AI in areas such as cybersecurity and sustainability. The partnership is also expected to drive innovation in the field of AI ethics and to promote the development of AI systems that are transparent, explainable, and fair. As the field of artificial intelligence continues to evolve, the partnership between Microsoft and OpenAI is likely to play a significant role in shaping the future of technology and ensuring that AI systems are developed and used in ways that benefit society.
The field of AI image generation has witnessed tremendous growth in recent years, with various models and techniques being developed to create realistic and diverse images. As reported by The Rundown AI, the latest advancements in this field have led to the emergence of a new top banana in AI image generation. This article will delve into the details of this new development and explore its potential applications.
Introduction to AI Image Generation
AI image generation refers to the use of artificial intelligence algorithms to create images that are similar to those produced by humans. This technology has numerous applications, including computer vision, robotics, and gaming. The process of AI image generation involves training a model on a large dataset of images, which enables it to learn patterns and features that can be used to generate new images.
The New Top Banana in AI Image Generation
According to The Rundown AI, the new top banana in AI image generation is a model developed by Anthropic, a leading AI research organization. This model has demonstrated exceptional capabilities in generating high-quality images that are comparable to those produced by humans. The model’s architecture is based on a combination of deep learning and machine learning techniques, which enables it to learn complex patterns and features from large datasets.
The new top banana in AI image generation has the potential to revolutionize the field of computer vision and enable the development of more sophisticated AI-powered applications.
Applications of AI Image Generation
The applications of AI image generation are diverse and widespread. Some of the most significant applications include computer vision, robotics, gaming, and healthcare. In computer vision, AI image generation can be used to create synthetic images that can be used to train models for object detection, segmentation, and recognition. In robotics, AI image generation can be used to create realistic simulations of environments, which can be used to train robots to navigate and interact with their surroundings.
Creating an AI Assistant with its Own Phone Number
In addition to AI image generation, The Rundown AI also provides information on how to create an AI assistant with its own phone number. This can be achieved using a combination of natural language processing and machine learning techniques, which enable the AI assistant to understand and respond to voice commands. The AI assistant can be integrated with various platforms, including GitHub, to enable seamless communication and interaction.
Conclusion
In conclusion, the new top banana in AI image generation has the potential to revolutionize the field of computer vision and enable the development of more sophisticated AI-powered applications. The applications of AI image generation are diverse and widespread, and the technology has the potential to transform various industries, including healthcare, gaming, and robotics. As reported by The Rundown AI, the future of AI image generation looks promising, and we can expect to see significant advancements in this field in the coming years.
The concept of intelligence ownership has been gaining traction in recent years, and for good reason. As Cisco has demonstrated, owning intelligence rather than renting it can be a game-changer for enterprises looking to scale their operations securely. According to a recent article by The Rundown AI, Cisco’s strategy to scale agents securely and reshape enterprise workflows is a prime example of this shift.
The Importance of Intelligence Ownership
Owning intelligence means having control over the data, algorithms, and insights that drive business decisions. This is particularly crucial in today’s fast-paced, data-driven world, where artificial intelligence and machine learning are becoming increasingly prevalent. By owning their intelligence, enterprises can ensure that their systems are secure, transparent, and aligned with their overall goals.
Scaling Agents Securely with Cisco
Cisco’s approach to scaling agents securely is centered around the idea of intelligence ownership. By developing and owning their own AI-powered agents, Cisco is able to ensure that their systems are secure, efficient, and tailored to their specific needs. This approach has allowed Cisco to reshape their enterprise workflows and improve overall productivity. As AWS and other cloud providers continue to evolve, the importance of owning intelligence will only continue to grow.
Cisco’s strategy is a great example of how owning intelligence can help enterprises scale their operations securely and efficiently. By taking control of their data and algorithms, companies can ensure that their systems are aligned with their overall goals and values.
The Benefits of Owning Intelligence
So why should enterprises prioritize intelligence ownership? The benefits are numerous. For one, owning intelligence provides a level of control and transparency that is difficult to achieve with rented intelligence. It also allows enterprises to develop systems that are tailored to their specific needs and goals, rather than relying on generic, off-the-shelf solutions. Additionally, owning intelligence can help enterprises to improve their overall security posture, as they are able to develop and implement their own security protocols and measures.
In contrast, rented intelligence can be limiting and inflexible. When enterprises rely on rented intelligence, they are often at the mercy of the provider, with limited control over the data, algorithms, and insights that drive their business decisions. This can lead to a lack of transparency, security risks, and a general sense of disempowerment.
Real-World Applications
So what does intelligence ownership look like in practice? One example is the development of custom GitHub repositories, which allow enterprises to own and control their code and data. Another example is the use of Azure and other cloud platforms to develop and deploy custom AI-powered solutions. By taking control of their intelligence, enterprises can develop systems that are tailored to their specific needs and goals, and that provide a level of security, transparency, and efficiency that is difficult to achieve with rented intelligence.