For graduate students, academics, and researchers, the process of conducting a thorough literature review can be a monumental task. Sifting through countless papers, managing sources, and extracting key insights often takes weeks, if not months. This is where Bohrium AI emerges as a revolutionary, free-to-use platform, designed to streamline this entire process. Also known as Science Navigator, this powerful tool, which has been gaining traction outside the Middle East, offers an incredible suite of features that can transform your academic workflow from a daunting chore into an efficient, insightful journey.
What is Bohrium AI (Science Navigator)?
At its core, Bohrium AI is an academic search engine specifically built for scientists and researchers. However, it’s far more than a simple search bar. Powered by advanced artificial intelligence, including models like DeepThink which are claimed to be smarter than GPT-4 for research tasks, the platform acts as a comprehensive assistant. Its primary goal is to help users solve scientific problems by providing deep access to a vast repository of academic knowledge. While its main search tool is branded as “Science Navigator,” the entire ecosystem of tools falls under the Bohrium umbrella.
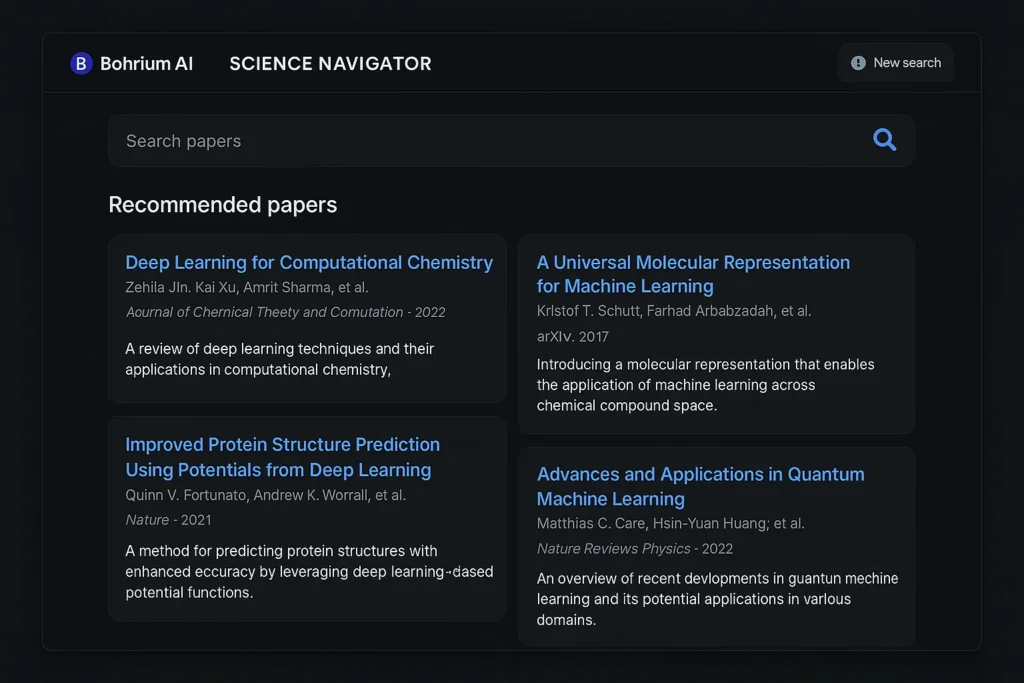
The clean and powerful interface of Bohrium AI’s Science Navigator.
Key Features of the Bohrium AI Platform
Bohrium isn’t just one tool; it’s a collection of integrated features that work together to create a seamless research experience. Here’s a breakdown of what makes it so powerful.
A Massive Database of 160 Million+ Papers
The most impressive feature of Bohrium is its sheer scale. The platform gives you access to a staggering 160 million research papers across a multitude of disciplines. This isn’t limited to just STEM fields; you can easily search for papers in areas like:
Natural Sciences (17 million papers)
Engineering Technology (13 million papers)
Life Sciences (31 million papers)
Philosophy & Social Sciences (9 million papers), including law, economics, and psychology.
This vast, interdisciplinary database ensures that no matter your field, you have a world of knowledge at your fingertips—completely free of charge.
Advanced AI-Powered Search & Filtering
Science Navigator allows you to go beyond simple keyword searches. You can ask complex scientific questions and receive detailed, summarized answers pulled directly from relevant literature. The results are not just a list of links; they are synthesized responses complete with citations, images, and charts embedded directly from the source papers. Furthermore, you can refine your search with robust filters, sorting results by:
Relevance or Quality: Prioritize the most relevant papers or the ones with the highest academic quality (based on citations and impact factor).
Date Range: Narrow down research to specific time periods.
Citations & Impact Factor: Find the most influential papers in a field.
Interactive “Chat with Papers” Functionality
This is arguably one of Bohrium AI’s most innovative features. Instead of reading papers one by one, you can select multiple articles from your search results and open them in a single chat interface. From there, you can ask questions and the AI will synthesize answers based on the collective knowledge of all the selected papers. For example, after selecting four relevant papers, you could ask, “How do these papers collectively define the challenges of AI in personalized learning?” The AI will then provide a comparative summary, even highlighting which papers are most relevant to your specific question.
Chat with multiple papers at once to synthesize information effortlessly.
Excellent Arabic Language Support
A significant advantage, especially for researchers in the MENA region, is Bohrium’s strong support for the Arabic language. You can input your search queries directly in Arabic and the platform will understand and fetch relevant results. It also provides on-the-fly translation of abstracts and key sections, breaking down language barriers and making global research more accessible. This commitment to multilingual support makes it an invaluable resource for non-native English speakers.
Personalized Research Hub: Library & Subscriptions
Bohrium helps you stay organized and up-to-date with several key features:
Knowledge Base: Create your own personal library by saving papers that are important to your research.
Subscriptions: You can “subscribe” to specific journals, keywords, or even individual scholars. This ensures you are notified whenever new research matching your interests is published.
Scholar Profiles: The platform contains profiles for over 20 million scholars, allowing you to follow their work or even claim your own profile to showcase your publications.
Looking for more ways to enhance your academic work? Check out our reviews of the best AI tools for students and researchers.
Is Bohrium AI Worth It?
Absolutely. For any graduate student, academic, or researcher, Bohrium AI is more than just a tool; it’s a comprehensive research partner. By offering free access to a massive database, advanced AI analysis, multi-paper chat, and excellent language support, it eliminates many of the traditional barriers to effective research. It saves an immense amount of time, reduces costs, and ultimately empowers you to focus on what truly matters: generating new insights and advancing your field. If you’re serious about academic research, giving Bohrium a try isn’t just recommended—it’s essential.
The recent joint statement from Microsoft and OpenAI has reaffirmed their long-term AI partnership, as reported by FutureTools News. This commitment to collaboration is expected to drive innovation in the field of artificial intelligence and shape the future of technology. The partnership between Microsoft and OpenAI has been instrumental in developing cutting-edge AI solutions, including the integration of OpenAI’s models with Microsoft’s Azure cloud platform.
Background of the Partnership
The partnership between Microsoft and OpenAI was formed with the goal of advancing the field of artificial intelligence and developing new technologies that can benefit society. The collaboration has led to significant breakthroughs in areas such as natural language processing and computer vision. The joint statement from Microsoft and OpenAI emphasizes their shared commitment to responsible AI development and the importance of ensuring that AI systems are aligned with human values.
Key Areas of Focus
The partnership between Microsoft and OpenAI is focused on several key areas, including the development of large language models and the integration of AI with other technologies such as GitHub and AWS. The goal is to create AI systems that can learn and improve over time, and that can be used to solve complex problems in areas such as healthcare and education. As stated by a Microsoft spokesperson,
The partnership between Microsoft and OpenAI is a key part of our strategy to advance the field of artificial intelligence and to develop new technologies that can benefit society. We are committed to working together to ensure that AI systems are developed and used in ways that are responsible and aligned with human values.
Future Directions
The joint statement from Microsoft and OpenAI also highlights their plans for future collaboration and innovation. The partners are expected to continue working together to develop new AI technologies and to explore new applications for AI in areas such as cybersecurity and sustainability. The partnership is also expected to drive innovation in the field of AI ethics and to promote the development of AI systems that are transparent, explainable, and fair. As the field of artificial intelligence continues to evolve, the partnership between Microsoft and OpenAI is likely to play a significant role in shaping the future of technology and ensuring that AI systems are developed and used in ways that benefit society.
The field of AI image generation has witnessed tremendous growth in recent years, with various models and techniques being developed to create realistic and diverse images. As reported by The Rundown AI, the latest advancements in this field have led to the emergence of a new top banana in AI image generation. This article will delve into the details of this new development and explore its potential applications.
Introduction to AI Image Generation
AI image generation refers to the use of artificial intelligence algorithms to create images that are similar to those produced by humans. This technology has numerous applications, including computer vision, robotics, and gaming. The process of AI image generation involves training a model on a large dataset of images, which enables it to learn patterns and features that can be used to generate new images.
The New Top Banana in AI Image Generation
According to The Rundown AI, the new top banana in AI image generation is a model developed by Anthropic, a leading AI research organization. This model has demonstrated exceptional capabilities in generating high-quality images that are comparable to those produced by humans. The model’s architecture is based on a combination of deep learning and machine learning techniques, which enables it to learn complex patterns and features from large datasets.
The new top banana in AI image generation has the potential to revolutionize the field of computer vision and enable the development of more sophisticated AI-powered applications.
Applications of AI Image Generation
The applications of AI image generation are diverse and widespread. Some of the most significant applications include computer vision, robotics, gaming, and healthcare. In computer vision, AI image generation can be used to create synthetic images that can be used to train models for object detection, segmentation, and recognition. In robotics, AI image generation can be used to create realistic simulations of environments, which can be used to train robots to navigate and interact with their surroundings.
Creating an AI Assistant with its Own Phone Number
In addition to AI image generation, The Rundown AI also provides information on how to create an AI assistant with its own phone number. This can be achieved using a combination of natural language processing and machine learning techniques, which enable the AI assistant to understand and respond to voice commands. The AI assistant can be integrated with various platforms, including GitHub, to enable seamless communication and interaction.
Conclusion
In conclusion, the new top banana in AI image generation has the potential to revolutionize the field of computer vision and enable the development of more sophisticated AI-powered applications. The applications of AI image generation are diverse and widespread, and the technology has the potential to transform various industries, including healthcare, gaming, and robotics. As reported by The Rundown AI, the future of AI image generation looks promising, and we can expect to see significant advancements in this field in the coming years.
The concept of intelligence ownership has been gaining traction in recent years, and for good reason. As Cisco has demonstrated, owning intelligence rather than renting it can be a game-changer for enterprises looking to scale their operations securely. According to a recent article by The Rundown AI, Cisco’s strategy to scale agents securely and reshape enterprise workflows is a prime example of this shift.
The Importance of Intelligence Ownership
Owning intelligence means having control over the data, algorithms, and insights that drive business decisions. This is particularly crucial in today’s fast-paced, data-driven world, where artificial intelligence and machine learning are becoming increasingly prevalent. By owning their intelligence, enterprises can ensure that their systems are secure, transparent, and aligned with their overall goals.
Scaling Agents Securely with Cisco
Cisco’s approach to scaling agents securely is centered around the idea of intelligence ownership. By developing and owning their own AI-powered agents, Cisco is able to ensure that their systems are secure, efficient, and tailored to their specific needs. This approach has allowed Cisco to reshape their enterprise workflows and improve overall productivity. As AWS and other cloud providers continue to evolve, the importance of owning intelligence will only continue to grow.
Cisco’s strategy is a great example of how owning intelligence can help enterprises scale their operations securely and efficiently. By taking control of their data and algorithms, companies can ensure that their systems are aligned with their overall goals and values.
The Benefits of Owning Intelligence
So why should enterprises prioritize intelligence ownership? The benefits are numerous. For one, owning intelligence provides a level of control and transparency that is difficult to achieve with rented intelligence. It also allows enterprises to develop systems that are tailored to their specific needs and goals, rather than relying on generic, off-the-shelf solutions. Additionally, owning intelligence can help enterprises to improve their overall security posture, as they are able to develop and implement their own security protocols and measures.
In contrast, rented intelligence can be limiting and inflexible. When enterprises rely on rented intelligence, they are often at the mercy of the provider, with limited control over the data, algorithms, and insights that drive their business decisions. This can lead to a lack of transparency, security risks, and a general sense of disempowerment.
Real-World Applications
So what does intelligence ownership look like in practice? One example is the development of custom GitHub repositories, which allow enterprises to own and control their code and data. Another example is the use of Azure and other cloud platforms to develop and deploy custom AI-powered solutions. By taking control of their intelligence, enterprises can develop systems that are tailored to their specific needs and goals, and that provide a level of security, transparency, and efficiency that is difficult to achieve with rented intelligence.