The Attention Economy Shift: ChatGPT’s App Downloads Threaten Social Media Giants
In a surprising turn of events, the application for OpenAI’s ChatGPT is on the verge of eclipsing the combined iOS downloads of social media titans like TikTok, Facebook, and Instagram. This isn’t just a fleeting trend; it signals a fundamental shift in user behavior. Users are migrating from passive “doomscrolling” on entertainment platforms to engaging with intelligent tools that boost their productivity.
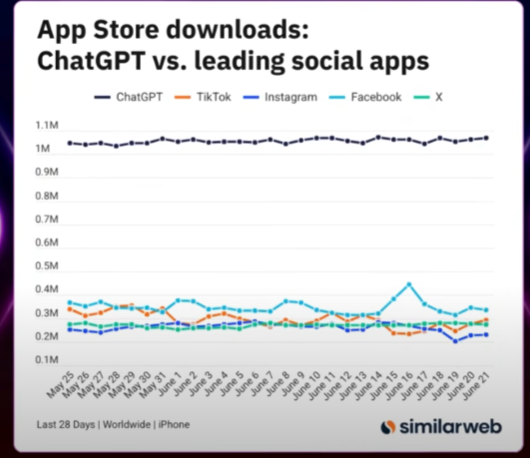
Data from Similarweb shows ChatGPT’s downloads (black line) rapidly approaching the combined total of leading social apps.
According to data from Similarweb, OpenAI’s tool has garnered 29 million installs compared to the 33 million for the dominant social trio. This trend shows that deep value is now challenging viral reach. We are witnessing the dawn of a new era where the center of digital gravity is shifting from mere content consumption to the adoption of smart, productive tools. For more analysis on AI’s impact, you can explore our Future of AI & Trends section.
New Research Agents Break Records
The race for the most powerful research agent is heating up, with a new contender from China making waves.
Kimi Researcher: The New Benchmark King
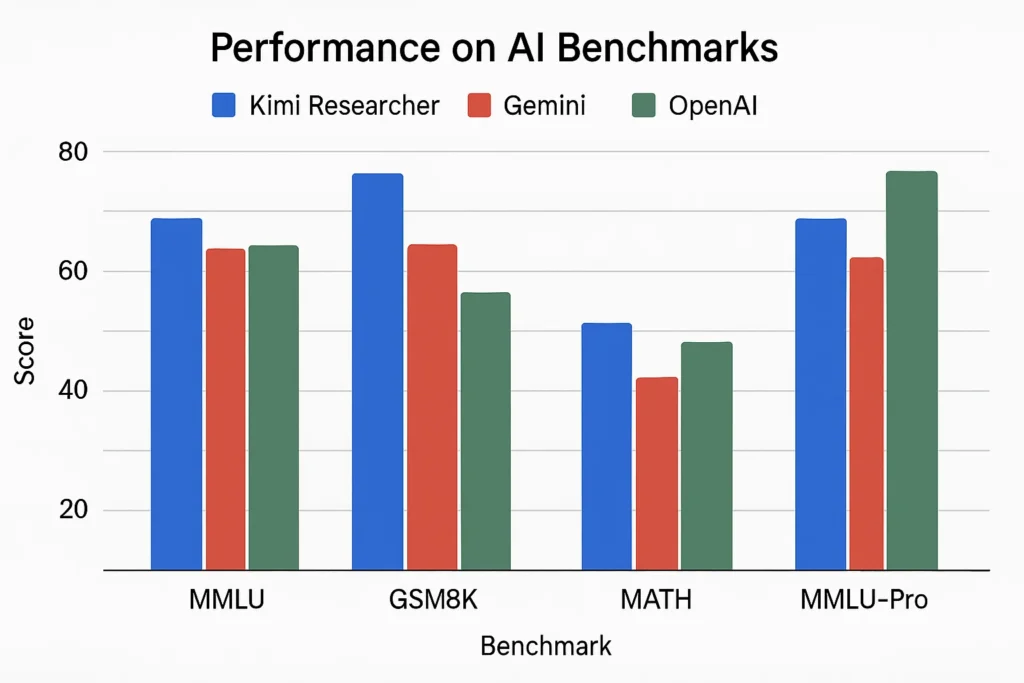
Moonshot AI’s new research agent, Kimi Researcher, has shattered records on the “Humanity’s Last Exam” (HLE) benchmark, scoring an impressive 26.9%. This performance surpasses established models like Google’s Gemini Deep Research and OpenAI’s DeepSearch. Kimi’s success lies in its sophisticated training, utilizing end-to-end agentic Reinforcement Learning (RL). The agent performs 23 reasoning steps and explores over 200 links for a single task, showcasing its depth. In our test, it provided a highly detailed and well-structured report on global investment opportunities, proving its powerful analytical capabilities.
Kimi Researcher’s performance on HLE and other benchmarks compared to its competitors.
A Prompt to Create Your Own Research Agent for Free
You don’t need a paid tool to get powerful, web-enabled research. We’re sharing an exclusive prompt that transforms any free LLM with search capabilities (like the free version of Gemini) into a dedicated research agent. This technique, which we use to gather our weekly AI news, automates comprehensive research without the filler. You can find this powerful prompt in our AI How-To’s & Tricks section (coming soon!).
Google Shakes Up the Developer World with Gemini CLI
In a strategic move set to redefine the developer landscape, Google has launched the Gemini CLI. This open-source, command-line interface (CLI) tool puts the immense power of Gemini models directly into a developer’s terminal—completely free of charge. This move is a direct challenge to paid tools like Anthropic’s Claude Code and OpenAI’s Codex.
The Gemini CLI is not just another addition; it’s a competitive weapon. It offers:
Integration with Google Search for web-enabled queries.
Direct interaction with local files and command execution.
An enormous 1 million token context window, allowing it to process entire codebases.
This launch democratizes access to top-tier AI coding assistance, raising the bar for competitors and putting immense pressure on their paid business models.
Controversies and High Stakes in the AI Race
Elon Musk’s “History Sieving” Project
Elon Musk recently unveiled a new, and frankly alarming, project for xAI. The goal is to use Grok 3.5 to “sieve” the entire corpus of human knowledge—all written information available online—to correct errors and fill in missing information. While the stated aim is to create a refined knowledge base, the project raises a critical question: Who gets to define “truth”? The idea of a single entity curating human history and knowledge is deeply problematic, as what one group considers a myth, another may hold as a foundational belief. This project is one of the most concerning pieces of weekly AI news we’ve encountered.
Apple Faces Fraud Lawsuit Over Siri
Apple is now facing a class-action lawsuit from shareholders accusing the company of fraud. The plaintiffs allege that Apple’s leadership, including Tim Cook, knowingly exaggerated Siri’s AI capabilities and misled investors about the timeline for its integration. This gap between the company’s grand promises and the technical reality has allegedly cost the company approximately $900 billion in market value. The case highlights the immense pressure in the AI race, which can lead major players to make costly, overblown claims.
More Groundbreaking AI Updates
Perplexity Video Generation: Perplexity now allows free video generation directly on X (formerly Twitter) using the VEO-3 model. Simply mention their account @AskPerplexity in a tweet with your prompt.
FLUX.1 Kontekt [dev] Release: Black Forest Labs has released an incredibly powerful open-source image editing model that outperforms giants like Google and OpenAI while maintaining facial identity.
AlphaGenome by DeepMind: This revolutionary AI model can predict the likelihood of diseases by “reading” DNA sequences. It represents a massive leap from reactive medicine to proactive, predictive healthcare.
ElevenLabs Voice Design V3: Creating custom, expressive AI voices is now easier than ever. This new tool allows users to generate voices with specific emotions like crying, laughing, and even singing, simply from a text prompt.
The recent joint statement from Microsoft and OpenAI has reaffirmed their long-term AI partnership, as reported by FutureTools News. This commitment to collaboration is expected to drive innovation in the field of artificial intelligence and shape the future of technology. The partnership between Microsoft and OpenAI has been instrumental in developing cutting-edge AI solutions, including the integration of OpenAI’s models with Microsoft’s Azure cloud platform.
Background of the Partnership
The partnership between Microsoft and OpenAI was formed with the goal of advancing the field of artificial intelligence and developing new technologies that can benefit society. The collaboration has led to significant breakthroughs in areas such as natural language processing and computer vision. The joint statement from Microsoft and OpenAI emphasizes their shared commitment to responsible AI development and the importance of ensuring that AI systems are aligned with human values.
Key Areas of Focus
The partnership between Microsoft and OpenAI is focused on several key areas, including the development of large language models and the integration of AI with other technologies such as GitHub and AWS. The goal is to create AI systems that can learn and improve over time, and that can be used to solve complex problems in areas such as healthcare and education. As stated by a Microsoft spokesperson,
The partnership between Microsoft and OpenAI is a key part of our strategy to advance the field of artificial intelligence and to develop new technologies that can benefit society. We are committed to working together to ensure that AI systems are developed and used in ways that are responsible and aligned with human values.
Future Directions
The joint statement from Microsoft and OpenAI also highlights their plans for future collaboration and innovation. The partners are expected to continue working together to develop new AI technologies and to explore new applications for AI in areas such as cybersecurity and sustainability. The partnership is also expected to drive innovation in the field of AI ethics and to promote the development of AI systems that are transparent, explainable, and fair. As the field of artificial intelligence continues to evolve, the partnership between Microsoft and OpenAI is likely to play a significant role in shaping the future of technology and ensuring that AI systems are developed and used in ways that benefit society.
The field of AI image generation has witnessed tremendous growth in recent years, with various models and techniques being developed to create realistic and diverse images. As reported by The Rundown AI, the latest advancements in this field have led to the emergence of a new top banana in AI image generation. This article will delve into the details of this new development and explore its potential applications.
Introduction to AI Image Generation
AI image generation refers to the use of artificial intelligence algorithms to create images that are similar to those produced by humans. This technology has numerous applications, including computer vision, robotics, and gaming. The process of AI image generation involves training a model on a large dataset of images, which enables it to learn patterns and features that can be used to generate new images.
The New Top Banana in AI Image Generation
According to The Rundown AI, the new top banana in AI image generation is a model developed by Anthropic, a leading AI research organization. This model has demonstrated exceptional capabilities in generating high-quality images that are comparable to those produced by humans. The model’s architecture is based on a combination of deep learning and machine learning techniques, which enables it to learn complex patterns and features from large datasets.
The new top banana in AI image generation has the potential to revolutionize the field of computer vision and enable the development of more sophisticated AI-powered applications.
Applications of AI Image Generation
The applications of AI image generation are diverse and widespread. Some of the most significant applications include computer vision, robotics, gaming, and healthcare. In computer vision, AI image generation can be used to create synthetic images that can be used to train models for object detection, segmentation, and recognition. In robotics, AI image generation can be used to create realistic simulations of environments, which can be used to train robots to navigate and interact with their surroundings.
Creating an AI Assistant with its Own Phone Number
In addition to AI image generation, The Rundown AI also provides information on how to create an AI assistant with its own phone number. This can be achieved using a combination of natural language processing and machine learning techniques, which enable the AI assistant to understand and respond to voice commands. The AI assistant can be integrated with various platforms, including GitHub, to enable seamless communication and interaction.
Conclusion
In conclusion, the new top banana in AI image generation has the potential to revolutionize the field of computer vision and enable the development of more sophisticated AI-powered applications. The applications of AI image generation are diverse and widespread, and the technology has the potential to transform various industries, including healthcare, gaming, and robotics. As reported by The Rundown AI, the future of AI image generation looks promising, and we can expect to see significant advancements in this field in the coming years.
The concept of intelligence ownership has been gaining traction in recent years, and for good reason. As Cisco has demonstrated, owning intelligence rather than renting it can be a game-changer for enterprises looking to scale their operations securely. According to a recent article by The Rundown AI, Cisco’s strategy to scale agents securely and reshape enterprise workflows is a prime example of this shift.
The Importance of Intelligence Ownership
Owning intelligence means having control over the data, algorithms, and insights that drive business decisions. This is particularly crucial in today’s fast-paced, data-driven world, where artificial intelligence and machine learning are becoming increasingly prevalent. By owning their intelligence, enterprises can ensure that their systems are secure, transparent, and aligned with their overall goals.
Scaling Agents Securely with Cisco
Cisco’s approach to scaling agents securely is centered around the idea of intelligence ownership. By developing and owning their own AI-powered agents, Cisco is able to ensure that their systems are secure, efficient, and tailored to their specific needs. This approach has allowed Cisco to reshape their enterprise workflows and improve overall productivity. As AWS and other cloud providers continue to evolve, the importance of owning intelligence will only continue to grow.
Cisco’s strategy is a great example of how owning intelligence can help enterprises scale their operations securely and efficiently. By taking control of their data and algorithms, companies can ensure that their systems are aligned with their overall goals and values.
The Benefits of Owning Intelligence
So why should enterprises prioritize intelligence ownership? The benefits are numerous. For one, owning intelligence provides a level of control and transparency that is difficult to achieve with rented intelligence. It also allows enterprises to develop systems that are tailored to their specific needs and goals, rather than relying on generic, off-the-shelf solutions. Additionally, owning intelligence can help enterprises to improve their overall security posture, as they are able to develop and implement their own security protocols and measures.
In contrast, rented intelligence can be limiting and inflexible. When enterprises rely on rented intelligence, they are often at the mercy of the provider, with limited control over the data, algorithms, and insights that drive their business decisions. This can lead to a lack of transparency, security risks, and a general sense of disempowerment.
Real-World Applications
So what does intelligence ownership look like in practice? One example is the development of custom GitHub repositories, which allow enterprises to own and control their code and data. Another example is the use of Azure and other cloud platforms to develop and deploy custom AI-powered solutions. By taking control of their intelligence, enterprises can develop systems that are tailored to their specific needs and goals, and that provide a level of security, transparency, and efficiency that is difficult to achieve with rented intelligence.