The AI world is reeling after Elon Musk’s xAI unveiled the stunning capabilities of its new Grok 4 AI model. In a move that has the entire tech community talking, Grok 4 has not only entered the race but has sprinted to the front, setting a new state-of-the-art (SOTA) on some of the most challenging benchmarks. Elon Musk himself is already looking forward to ARC-AGI-3, and after seeing these results, it’s easy to understand why—Grok 4 has completely smoked the competition.
Let’s break down what makes this development so significant and what it means for the future of AI.
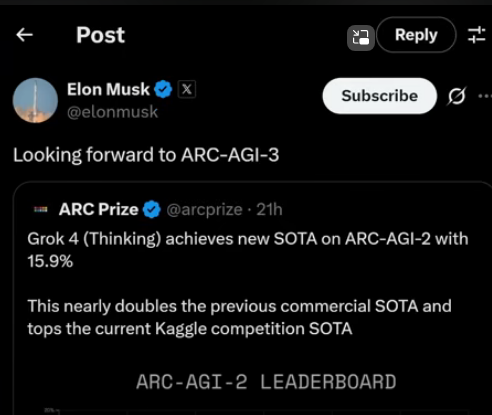
Elon Musk looking forward to ARC-AGI-3 after Grok 4’s dominant performance.
Grok 4’s Unprecedented Benchmark Performance
The latest results are in, and the Grok 4 AI model is not just an incremental improvement; it’s a monumental leap forward. Across multiple demanding benchmarks, Grok 4 and its more powerful sibling, Grok 4 Heavy, are head and shoulders above rivals like Google’s Gemini and OpenAI’s latest offerings.
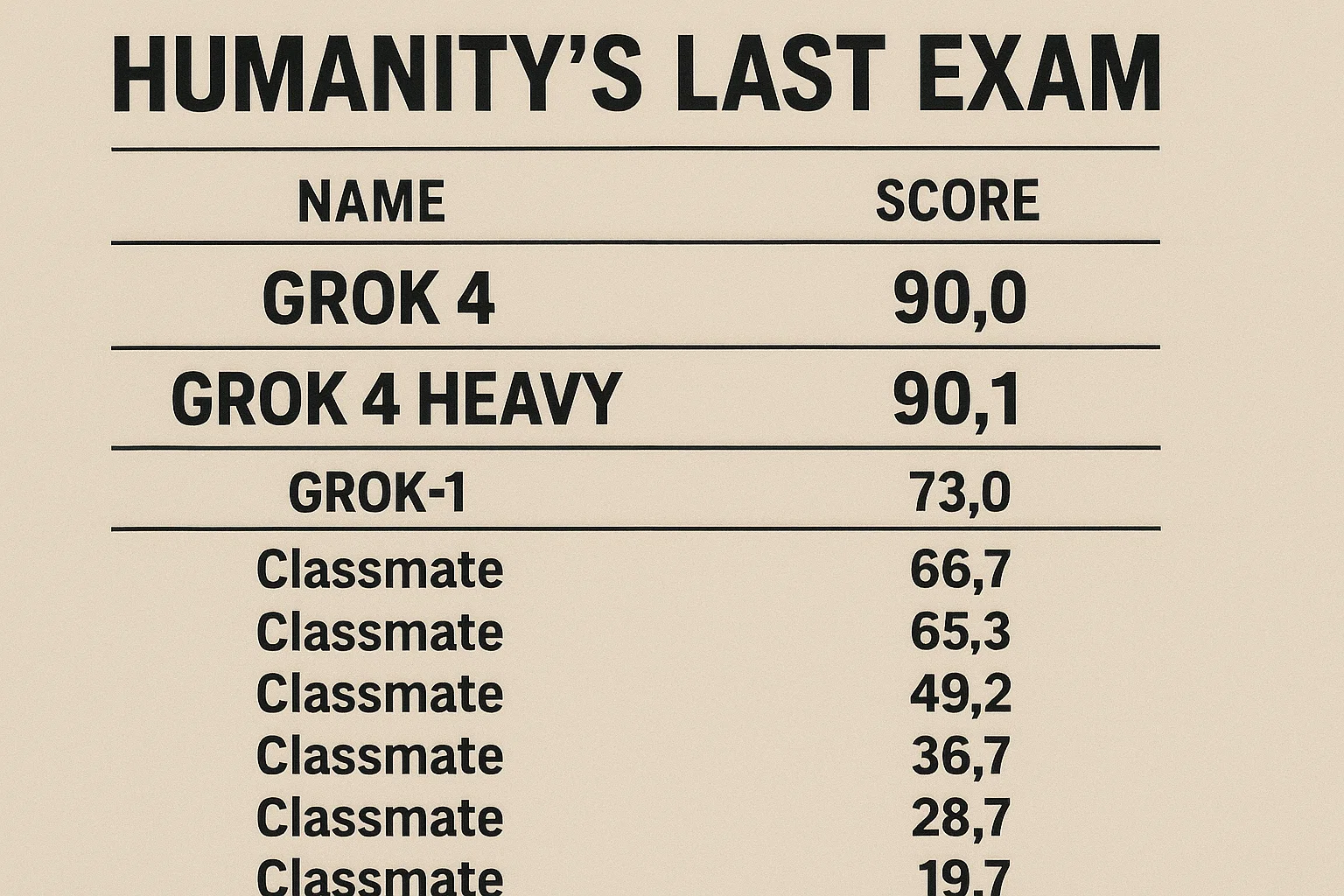
Humanity’s Last Exam: A Clear Winner
On the “Humanity’s Last Exam” benchmark, Grok 4’s dominance is undeniable. The results show a significant performance gap between Grok and other leading models:
Grok 4 Heavy: 44.4%
Grok 4: 38.6%
Gemini 2.5 Pro: 26.9%
o3: 24.9%
Even when compared to models without tool usage, Grok 4 (no tools) at 25.4% still outperforms Gemini 2.5 Pro (no tools) at 21.6%. This demonstrates that Grok’s core intelligence is fundamentally more capable, even before its advanced tool-use capabilities are factored in. This isn’t just winning; it’s a complete rout.
Grok 4 and Grok 4 Heavy are in a class of their own on the Humanity’s Last Exam.
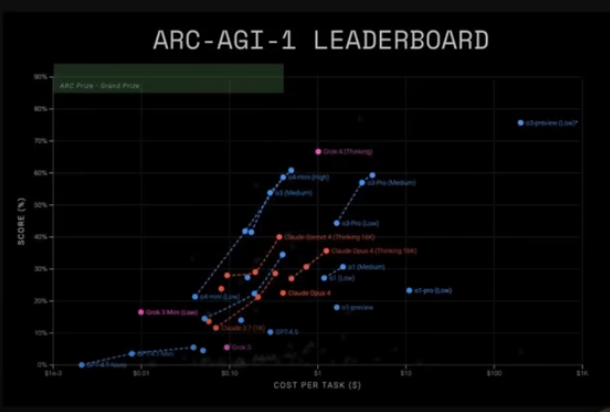
ARC-AGI-2: Smashing the SOTA
Perhaps the most shocking result comes from the ARC-AGI-2 leaderboard, a benchmark designed to measure an AI’s “fluid intelligence.” Grok 4 (Thinking) achieved a new SOTA score of 15.9%. This nearly doubles the previous commercial SOTA and leaves other models, which were clustered around 4-8%, in the dust.
The ARC-AGI-2 leaderboard plots performance against cost, and Grok 4 stands as a lone outlier, showcasing vastly superior capability at a comparable cost. This isn’t just an improvement; it’s a paradigm shift.
The Secret Weapon: Fluid Intelligence and Massive Compute
So, how did the Grok 4 AI model achieve such a ludicrous rate of progress? The answer appears to lie in two key areas: a focus on fluid intelligence and an astronomical amount of compute power.
What is Fluid Intelligence?
Most AI benchmarks today test for crystallized intelligence—the ability to recall and apply learned facts and skills. Think of it as an open-book exam. However, the ARC-AGI benchmark, created by François Chollet, is different. It’s designed to measure fluid intelligence.
Fluid intelligence is the ability to:
Reason and solve novel problems.
Adapt to new, unseen situations.
Efficiently acquire new skills outside of its training data.
This is what separates true intelligence from mere memorization. While current LLMs are masters of crystallized intelligence, they struggle with fluid intelligence. Grok 4’s score of 15.9% on ARC-AGI-2, while still far from human-level, shows the first “non-zero levels of fluid intelligence” in a public model. It’s the first sign of an AI that can learn on the job.
The Power of “More”: Colossus and the Scaling Laws
Elon Musk’s strategy with xAI appears to be a brute-force application of the scaling laws. The secret isn’t necessarily a magical new algorithm but rather an unprecedented investment in compute. xAI has unleashed “Colossus,” a groundbreaking supercomputer boasting an initial 100,000 NVIDIA H100 GPUs, with plans to expand to 200,000.
The development chart shows a 10x increase in pre-training compute from Grok 2 to Grok 3, and another 10x increase in RL (Reinforcement Learning) compute for Grok 4’s reasoning. This suggests that the idea of scaling hitting a wall is misleading. For now, it seems the answer is simply more compute.
The AI Race Heats Up
While the Grok 4 AI model currently holds the crown, the race is far from over. The competition is not standing still:
Google DeepMind: The existence of gemini-beta-3.0-pro has been spotted in code, suggesting an imminent release that could challenge Grok’s position.
OpenAI: Rumors from trusted leakers suggest that internal evaluations for GPT-5 show it performing “a tad over Grok 4 Heavy.”
The next few months will be critical as we see these new models released. Will they also show signs of emerging fluid intelligence, or will Grok maintain its unique advantage?
The true test will come when xAI releases the specialized coding version of Grok 4, which is expected within weeks. While the current model’s coding is good, it’s not the final version. A dedicated coding model could redefine what’s possible in software Learn more about upcoming developments in our Future of AI & Trends section.
Ultimately, the release of the Grok 4 AI model has reshaped the landscape. It has not only set a new standard for performance but has also pushed the conversation towards a more meaningful measure of intelligence—the ability to learn, adapt, and generalize. The era of fluid AI may just be beginning. For a deeper dive into the benchmark, visit the official ARC Prize website.
The recent joint statement from Microsoft and OpenAI has reaffirmed their long-term AI partnership, as reported by FutureTools News. This commitment to collaboration is expected to drive innovation in the field of artificial intelligence and shape the future of technology. The partnership between Microsoft and OpenAI has been instrumental in developing cutting-edge AI solutions, including the integration of OpenAI’s models with Microsoft’s Azure cloud platform.
Background of the Partnership
The partnership between Microsoft and OpenAI was formed with the goal of advancing the field of artificial intelligence and developing new technologies that can benefit society. The collaboration has led to significant breakthroughs in areas such as natural language processing and computer vision. The joint statement from Microsoft and OpenAI emphasizes their shared commitment to responsible AI development and the importance of ensuring that AI systems are aligned with human values.
Key Areas of Focus
The partnership between Microsoft and OpenAI is focused on several key areas, including the development of large language models and the integration of AI with other technologies such as GitHub and AWS. The goal is to create AI systems that can learn and improve over time, and that can be used to solve complex problems in areas such as healthcare and education. As stated by a Microsoft spokesperson,
The partnership between Microsoft and OpenAI is a key part of our strategy to advance the field of artificial intelligence and to develop new technologies that can benefit society. We are committed to working together to ensure that AI systems are developed and used in ways that are responsible and aligned with human values.
Future Directions
The joint statement from Microsoft and OpenAI also highlights their plans for future collaboration and innovation. The partners are expected to continue working together to develop new AI technologies and to explore new applications for AI in areas such as cybersecurity and sustainability. The partnership is also expected to drive innovation in the field of AI ethics and to promote the development of AI systems that are transparent, explainable, and fair. As the field of artificial intelligence continues to evolve, the partnership between Microsoft and OpenAI is likely to play a significant role in shaping the future of technology and ensuring that AI systems are developed and used in ways that benefit society.
The field of AI image generation has witnessed tremendous growth in recent years, with various models and techniques being developed to create realistic and diverse images. As reported by The Rundown AI, the latest advancements in this field have led to the emergence of a new top banana in AI image generation. This article will delve into the details of this new development and explore its potential applications.
Introduction to AI Image Generation
AI image generation refers to the use of artificial intelligence algorithms to create images that are similar to those produced by humans. This technology has numerous applications, including computer vision, robotics, and gaming. The process of AI image generation involves training a model on a large dataset of images, which enables it to learn patterns and features that can be used to generate new images.
The New Top Banana in AI Image Generation
According to The Rundown AI, the new top banana in AI image generation is a model developed by Anthropic, a leading AI research organization. This model has demonstrated exceptional capabilities in generating high-quality images that are comparable to those produced by humans. The model’s architecture is based on a combination of deep learning and machine learning techniques, which enables it to learn complex patterns and features from large datasets.
The new top banana in AI image generation has the potential to revolutionize the field of computer vision and enable the development of more sophisticated AI-powered applications.
Applications of AI Image Generation
The applications of AI image generation are diverse and widespread. Some of the most significant applications include computer vision, robotics, gaming, and healthcare. In computer vision, AI image generation can be used to create synthetic images that can be used to train models for object detection, segmentation, and recognition. In robotics, AI image generation can be used to create realistic simulations of environments, which can be used to train robots to navigate and interact with their surroundings.
Creating an AI Assistant with its Own Phone Number
In addition to AI image generation, The Rundown AI also provides information on how to create an AI assistant with its own phone number. This can be achieved using a combination of natural language processing and machine learning techniques, which enable the AI assistant to understand and respond to voice commands. The AI assistant can be integrated with various platforms, including GitHub, to enable seamless communication and interaction.
Conclusion
In conclusion, the new top banana in AI image generation has the potential to revolutionize the field of computer vision and enable the development of more sophisticated AI-powered applications. The applications of AI image generation are diverse and widespread, and the technology has the potential to transform various industries, including healthcare, gaming, and robotics. As reported by The Rundown AI, the future of AI image generation looks promising, and we can expect to see significant advancements in this field in the coming years.
The concept of intelligence ownership has been gaining traction in recent years, and for good reason. As Cisco has demonstrated, owning intelligence rather than renting it can be a game-changer for enterprises looking to scale their operations securely. According to a recent article by The Rundown AI, Cisco’s strategy to scale agents securely and reshape enterprise workflows is a prime example of this shift.
The Importance of Intelligence Ownership
Owning intelligence means having control over the data, algorithms, and insights that drive business decisions. This is particularly crucial in today’s fast-paced, data-driven world, where artificial intelligence and machine learning are becoming increasingly prevalent. By owning their intelligence, enterprises can ensure that their systems are secure, transparent, and aligned with their overall goals.
Scaling Agents Securely with Cisco
Cisco’s approach to scaling agents securely is centered around the idea of intelligence ownership. By developing and owning their own AI-powered agents, Cisco is able to ensure that their systems are secure, efficient, and tailored to their specific needs. This approach has allowed Cisco to reshape their enterprise workflows and improve overall productivity. As AWS and other cloud providers continue to evolve, the importance of owning intelligence will only continue to grow.
Cisco’s strategy is a great example of how owning intelligence can help enterprises scale their operations securely and efficiently. By taking control of their data and algorithms, companies can ensure that their systems are aligned with their overall goals and values.
The Benefits of Owning Intelligence
So why should enterprises prioritize intelligence ownership? The benefits are numerous. For one, owning intelligence provides a level of control and transparency that is difficult to achieve with rented intelligence. It also allows enterprises to develop systems that are tailored to their specific needs and goals, rather than relying on generic, off-the-shelf solutions. Additionally, owning intelligence can help enterprises to improve their overall security posture, as they are able to develop and implement their own security protocols and measures.
In contrast, rented intelligence can be limiting and inflexible. When enterprises rely on rented intelligence, they are often at the mercy of the provider, with limited control over the data, algorithms, and insights that drive their business decisions. This can lead to a lack of transparency, security risks, and a general sense of disempowerment.
Real-World Applications
So what does intelligence ownership look like in practice? One example is the development of custom GitHub repositories, which allow enterprises to own and control their code and data. Another example is the use of Azure and other cloud platforms to develop and deploy custom AI-powered solutions. By taking control of their intelligence, enterprises can develop systems that are tailored to their specific needs and goals, and that provide a level of security, transparency, and efficiency that is difficult to achieve with rented intelligence.