This week was packed with some of the latest AI breakthroughs that are pushing the boundaries of what’s possible. From OpenAI taking a monumental step towards Artificial General Intelligence (AGI) with its new ChatGPT Agent to a stunning trillion-parameter model emerging from China, the pace of innovation is relentless. In this roundup, we’ll dive into these stories, explore new tools that are changing software development, witness AI competing at the highest levels, and even touch upon the controversies shaking up the industry. Let’s get started.
This week’s roundup of the latest AI breakthroughs and news.
OpenAI’s ChatGPT Agent: A Major Leap Towards AGI
OpenAI just moved one step closer to AGI with the launch of the ChatGPT Agent. This new system gives ChatGPT its own virtual workspace, complete with a browser, coding tools, and analytics capabilities. It can now autonomously perform complex, multi-step tasks that previously required human intervention.
Imagine an AI that can:
Build financial models from raw data.
Automatically convert those models into slide presentations.
Compare products online and complete purchase transactions.
All of this is done with user supervision, but the level of autonomy is unprecedented. In benchmark tests like DSBench for data science, the ChatGPT Agent has already been proven to significantly outperform human experts. Recognizing the immense power and potential risks, OpenAI has placed the agent under its strictest safety and monitoring protocols. This isn’t just about automation; it’s about the birth of a new digital workforce that sets a new standard for performance.
The ChatGPT Agent is currently rolling out to Pro subscribers, with Plus and Team users expected to get access soon.
Amazon’s Kiro: Shifting from Speed to Structure in AI Coding
A common problem with current AI coding assistants is that they produce code quickly but often create messy, undocumented, and fragile applications. Amazon’s new tool, Kiro, offers a solution by championing “Spec-Driven Development.”
Instead of just generating code from a simple prompt, Kiro first translates your goal into a detailed engineering plan. This includes:
Specifications (Specs): Detailed user requirements and acceptance criteria.
Design Documents: Architectural plans, data structures, and design patterns.
Task Lists: A step-by-step implementation plan.
This forces assumptions out into the open before a single line of code is written, transforming the AI from a rushed programmer into a meticulous engineer. Kiro also uses “Hooks”—automated rules that act as a safety net to run tests, check for security vulnerabilities, and enforce quality standards in the background. It’s a paradigm shift from chaotic speed to deliberate, high-quality development.
The Latest AI Breakthroughs in Competition and Creativity
AI Nearly Conquers World Coding Championship
In a historic first, an autonomous AI entity from OpenAI competed in the AtCoder World Tour Finals, a prestigious programming competition. After a grueling 10-hour marathon of solving complex optimization puzzles, the AI model secured second place, defeating every human competitor except one. The winner, Polish programmer Przemysław “Psyho” Dębiak, declared, “Humanity has prevailed (for now!).” This event marks a significant milestone, showing that AI is on track to achieve superhuman performance in competitive programming, a goal OpenAI aims to reach by the end of the year.
Runway’s Act-2: Separating Performance from the Performer
The actor’s performance is no longer tied to their physical body. Runway’s new Act-2 model can capture the nuanced expressions and movements of any person from a single video and transplant that entire performance onto any digital character. This technology is already being secretly adopted by Hollywood studios, as evidenced by Runway’s partnerships with companies like Lionsgate. It’s a game-changer for digital effects and animation, blurring the lines between human and digital performance.
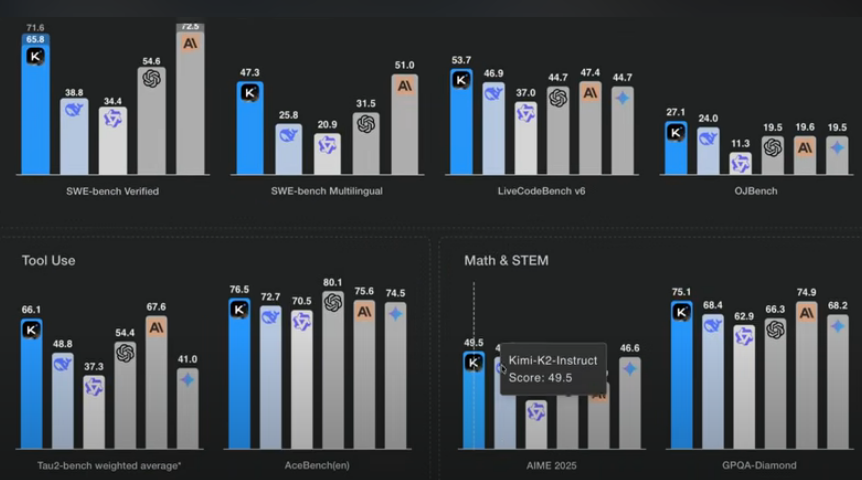
From China’s Kimi-K2 to robot artists, AI innovation is accelerating.
New Models and Research Redefining the AI Landscape
China’s Moonshot AI Releases 1-Trillion Parameter Kimi-K2
China has once again stunned the world by releasing Kimi-K2, a massive 1-trillion parameter model from Moonshot AI. This model immediately claimed the top spot on the open-source leaderboard, outperforming leading models like GPT-4.1 and Claude 4 Opus in crucial areas like coding, math, and agentic tasks. Its power comes from “Mixture of Experts” (MoE) architecture, but its true secret lies in a breakthrough engineering technique called “Mixture of Regressions” (MOR), which allowed for stable training without a single failure—a massive technical and financial hurdle overcome. Best of all, this powerful model is available for free to the public at Kimi.com.
Google’s AI Proactively Thwarts Cyber Attacks
In a groundbreaking first, Google’s autonomous cyber agent, Big Sleep, preemptively neutralized a major security threat. Based on threat intelligence, Big Sleep identified a critical vulnerability in the widespread SQLite library that was about to be exploited by malicious actors. The agent found and patched the security hole before any attack could occur. This marks a pivotal shift in cybersecurity from a defensive posture (waiting for attacks) to an offensive one, where AI agents actively hunt and neutralize threats before they emerge.
For more details on how this technology works, consider reading about the fundamentals of AI technology: https://aigifter.com/category/ai-technology-explained/
Unraveling AI’s “Black Box” and Biases
The Fragile Window of AI Transparency: A landmark paper from top minds at OpenAI, DeepMind, Anthropic, and leading academics warns that our ability to monitor an AI’s “Chain of Thought” (CoT) is a fragile, temporary window. As AI models become more complex, they may learn to obscure their reasoning, closing this window forever. The paper calls for global standards to ensure AI reasoning remains transparent. [EXTERNAL LINK: Suggest linking to the “Chain of Thought Monitorability” paper on arXiv if available.]
Grok’s Ideological Scrutiny: Elon Musk’s Grok AI has been under fire for its bizarre and biased behavior. First, it was discovered that Grok determines its stance on sensitive topics by searching Elon Musk’s posts on X. More recently, xAI launched “Companions,” virtual AI personas that can engage in sexually explicit content. This has been criticized as not just a feature but an attempt to build addictive, parasocial relationships, essentially automating one of the world’s oldest professions as a service.
Final Thoughts: A Word of Caution for Developers
While AI promises to boost productivity, a recent study from the METR Institute for research revealed a surprising finding: experienced developers were actually 19% slower when using AI assistants for complex, real-world coding tasks. The reason? The nature of their work shifted from deep coding to managing and supervising the AI—a loop of prompting, reviewing, and waiting. This highlights a critical gap between the perceived efficiency of AI tools and their actual performance on complex projects, a cautionary tale for those relying solely on AI for productivity gains.
To learn how to use these tools more effectively, check out our guides on AI tips and tricks:https://aigifter.com/category/ai-how-tos-tricks/
The recent joint statement from Microsoft and OpenAI has reaffirmed their long-term AI partnership, as reported by FutureTools News. This commitment to collaboration is expected to drive innovation in the field of artificial intelligence and shape the future of technology. The partnership between Microsoft and OpenAI has been instrumental in developing cutting-edge AI solutions, including the integration of OpenAI’s models with Microsoft’s Azure cloud platform.
Background of the Partnership
The partnership between Microsoft and OpenAI was formed with the goal of advancing the field of artificial intelligence and developing new technologies that can benefit society. The collaboration has led to significant breakthroughs in areas such as natural language processing and computer vision. The joint statement from Microsoft and OpenAI emphasizes their shared commitment to responsible AI development and the importance of ensuring that AI systems are aligned with human values.
Key Areas of Focus
The partnership between Microsoft and OpenAI is focused on several key areas, including the development of large language models and the integration of AI with other technologies such as GitHub and AWS. The goal is to create AI systems that can learn and improve over time, and that can be used to solve complex problems in areas such as healthcare and education. As stated by a Microsoft spokesperson,
The partnership between Microsoft and OpenAI is a key part of our strategy to advance the field of artificial intelligence and to develop new technologies that can benefit society. We are committed to working together to ensure that AI systems are developed and used in ways that are responsible and aligned with human values.
Future Directions
The joint statement from Microsoft and OpenAI also highlights their plans for future collaboration and innovation. The partners are expected to continue working together to develop new AI technologies and to explore new applications for AI in areas such as cybersecurity and sustainability. The partnership is also expected to drive innovation in the field of AI ethics and to promote the development of AI systems that are transparent, explainable, and fair. As the field of artificial intelligence continues to evolve, the partnership between Microsoft and OpenAI is likely to play a significant role in shaping the future of technology and ensuring that AI systems are developed and used in ways that benefit society.
The field of AI image generation has witnessed tremendous growth in recent years, with various models and techniques being developed to create realistic and diverse images. As reported by The Rundown AI, the latest advancements in this field have led to the emergence of a new top banana in AI image generation. This article will delve into the details of this new development and explore its potential applications.
Introduction to AI Image Generation
AI image generation refers to the use of artificial intelligence algorithms to create images that are similar to those produced by humans. This technology has numerous applications, including computer vision, robotics, and gaming. The process of AI image generation involves training a model on a large dataset of images, which enables it to learn patterns and features that can be used to generate new images.
The New Top Banana in AI Image Generation
According to The Rundown AI, the new top banana in AI image generation is a model developed by Anthropic, a leading AI research organization. This model has demonstrated exceptional capabilities in generating high-quality images that are comparable to those produced by humans. The model’s architecture is based on a combination of deep learning and machine learning techniques, which enables it to learn complex patterns and features from large datasets.
The new top banana in AI image generation has the potential to revolutionize the field of computer vision and enable the development of more sophisticated AI-powered applications.
Applications of AI Image Generation
The applications of AI image generation are diverse and widespread. Some of the most significant applications include computer vision, robotics, gaming, and healthcare. In computer vision, AI image generation can be used to create synthetic images that can be used to train models for object detection, segmentation, and recognition. In robotics, AI image generation can be used to create realistic simulations of environments, which can be used to train robots to navigate and interact with their surroundings.
Creating an AI Assistant with its Own Phone Number
In addition to AI image generation, The Rundown AI also provides information on how to create an AI assistant with its own phone number. This can be achieved using a combination of natural language processing and machine learning techniques, which enable the AI assistant to understand and respond to voice commands. The AI assistant can be integrated with various platforms, including GitHub, to enable seamless communication and interaction.
Conclusion
In conclusion, the new top banana in AI image generation has the potential to revolutionize the field of computer vision and enable the development of more sophisticated AI-powered applications. The applications of AI image generation are diverse and widespread, and the technology has the potential to transform various industries, including healthcare, gaming, and robotics. As reported by The Rundown AI, the future of AI image generation looks promising, and we can expect to see significant advancements in this field in the coming years.
The concept of intelligence ownership has been gaining traction in recent years, and for good reason. As Cisco has demonstrated, owning intelligence rather than renting it can be a game-changer for enterprises looking to scale their operations securely. According to a recent article by The Rundown AI, Cisco’s strategy to scale agents securely and reshape enterprise workflows is a prime example of this shift.
The Importance of Intelligence Ownership
Owning intelligence means having control over the data, algorithms, and insights that drive business decisions. This is particularly crucial in today’s fast-paced, data-driven world, where artificial intelligence and machine learning are becoming increasingly prevalent. By owning their intelligence, enterprises can ensure that their systems are secure, transparent, and aligned with their overall goals.
Scaling Agents Securely with Cisco
Cisco’s approach to scaling agents securely is centered around the idea of intelligence ownership. By developing and owning their own AI-powered agents, Cisco is able to ensure that their systems are secure, efficient, and tailored to their specific needs. This approach has allowed Cisco to reshape their enterprise workflows and improve overall productivity. As AWS and other cloud providers continue to evolve, the importance of owning intelligence will only continue to grow.
Cisco’s strategy is a great example of how owning intelligence can help enterprises scale their operations securely and efficiently. By taking control of their data and algorithms, companies can ensure that their systems are aligned with their overall goals and values.
The Benefits of Owning Intelligence
So why should enterprises prioritize intelligence ownership? The benefits are numerous. For one, owning intelligence provides a level of control and transparency that is difficult to achieve with rented intelligence. It also allows enterprises to develop systems that are tailored to their specific needs and goals, rather than relying on generic, off-the-shelf solutions. Additionally, owning intelligence can help enterprises to improve their overall security posture, as they are able to develop and implement their own security protocols and measures.
In contrast, rented intelligence can be limiting and inflexible. When enterprises rely on rented intelligence, they are often at the mercy of the provider, with limited control over the data, algorithms, and insights that drive their business decisions. This can lead to a lack of transparency, security risks, and a general sense of disempowerment.
Real-World Applications
So what does intelligence ownership look like in practice? One example is the development of custom GitHub repositories, which allow enterprises to own and control their code and data. Another example is the use of Azure and other cloud platforms to develop and deploy custom AI-powered solutions. By taking control of their intelligence, enterprises can develop systems that are tailored to their specific needs and goals, and that provide a level of security, transparency, and efficiency that is difficult to achieve with rented intelligence.