How often have you heard that robust security is just too expensive? While budget constraints are real, the latest data suggests a more urgent question: can we afford not to invest? The real cost of a data breach goes far beyond dollars and cents; it encompasses downtime, shattered reputation, and lost customer trust. Fortunately, we no longer need to rely on gut feelings. The IBM Cost of a Data Breach Report 2025 provides the hard numbers and critical insights businesses need to make informed security decisions, with a special focus on the growing role of Artificial Intelligence.
This comprehensive report isn’t theoretical. It’s built on in-depth interviews with nearly 3,500 leaders from 600 different organizations that have recently experienced a real-world data breach. Let’s dive into the key findings and what they mean for your organization’s security posture.
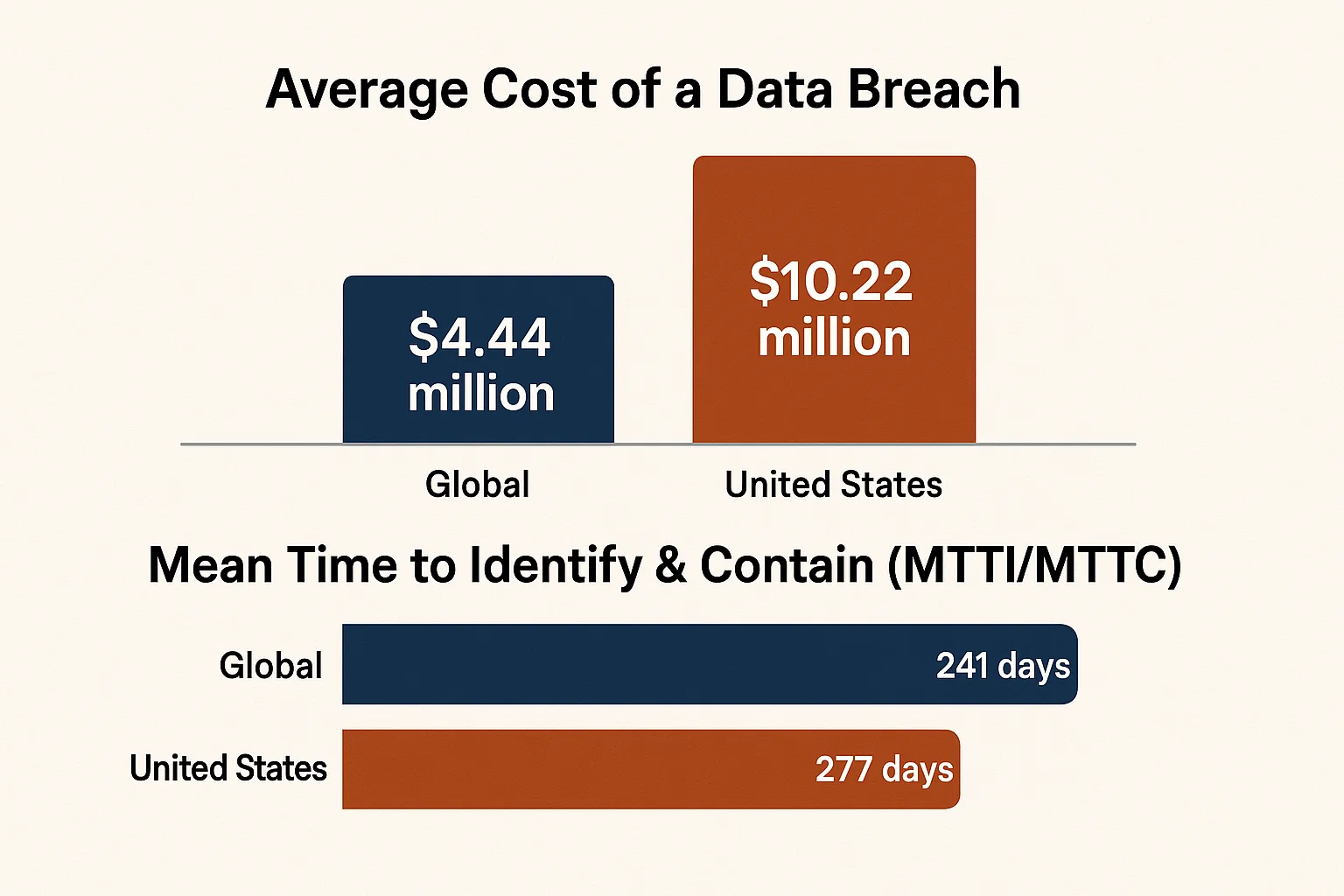
The global average cost of a data breach has seen a slight decrease, but the numbers in the US tell a different story.
The True Cost of a Data Breach in 2025: Key Findings
The latest report reveals a mixed bag of news. While there are signs of progress on a global scale, specific regions and attack vectors show concerning trends.
Global Trends vs. US Realities
There’s a sliver of good news for the world at large. The global average cost of a data breach actually decreased by 9%, settling at $4.44 million. This calculation excludes mega-breaches to avoid skewing the average, making it a realistic benchmark for most businesses.
Additionally, we’ve seen modest improvements in incident response times:
Mean Time to Identify & Contain (MTTI/MTTC): This crucial metric, which measures the total time from breach to containment, improved from 257 days down to 241 days. While still alarmingly long (the better part of a year), it’s a step in the right direction.
However, the situation in the United States is far more severe. The average cost of a data breach in the USA rose by 9% to a staggering $10.22 million—more than double the global average. This increase is driven by factors like rising regulatory fees and higher costs associated with breach detection.
Top Attack Vectors: The Weakest Links
Understanding how attackers get in is the first step to keeping them out. The report identified the most damaging and most frequent attack vectors:
Most Costly Breaches: The highest costs were associated with attacks originating from insider threats and compromised third-party systems. Insiders have the advantage of knowing the environment, allowing them to cause significant damage quickly.
Most Frequent Breaches: The most common initial attack vector, accounting for 16% of all breaches, remains phishing. This highlights that social engineering attacks targeting employees are still a massive and effective threat.
The AI Double-Edged Sword: Attacker vs. Defender
A major focus of this year’s report is the profound impact of Artificial Intelligence on cybersecurity—both as a weapon for attackers and a shield for defenders.
The Rise of Attacker AI
Attackers are rapidly adopting AI, and the results are alarming. 16% of all reported breaches were attributed to attackers using AI. These AI-powered attacks primarily manifest in two ways:
AI-Powered Phishing (37% of AI-related breaches): Research shows that what takes a skilled security professional 16 hours to craft, a generative AI chatbot can replicate in just 5 minutes. This allows attackers to create highly convincing, grammatically perfect phishing emails at an unprecedented scale.
Deepfakes (35% of AI-related breaches): The use of generative AI to create convincing imitations of a person’s voice, likeness, and image is a rapidly growing threat used to bypass security controls and manipulate employees.
Compounding this is the issue of “Shadow AI.” A concerning 20% of organizations discovered unauthorized AI implementations within their environments, creating unsecured and unmonitored entry points for attackers.
Organizations leveraging AI for security are seeing significant reductions in breach response times and costs.
How Your Organization Can Leverage AI for Defense
The news isn’t all bad. Organizations that are proactively and extensively using AI in their security operations are reaping massive benefits. Compared to organizations not using AI for security, those with mature AI security programs saw:
An 80-day faster breach identification and containment lifecycle.
An average cost savings of $1.9 million per breach.
The potential is clear, but a critical gap exists. A staggering 63% of organizations have no AI governance policy in place or are still in the early stages of developing one. Without a clear policy, success is left to chance.
Essential Recommendations to Mitigate Breach Costs
Based on these findings, the report offers clear recommendations for organizations looking to reduce their risk and minimize the potential cost of a data breach.
1. Strengthen Identity and Access Management (IAM)
Attackers find it easier to log in with stolen credentials than to hack their way in. Your defense must focus on strengthening authentication and authorization.
Manage Non-Human Identities (NHI): Focus on securing system-level accounts, API keys, and crypto keys. Implement a robust secrets management system to rotate these credentials regularly.
Adopt Passkeys: Move away from traditional passwords, which are vulnerable to phishing. Passkeys are a more secure, cryptography-based alternative that is highly resistant to these types of attacks.
2. Secure Your AI and Data Ecosystem
As AI becomes ubiquitous, securing it becomes non-negotiable. This requires a multi-layered approach.
Discover the Shadows: Implement tools to automatically discover all instances of data and AI usage across your organization, eliminating “Shadow AI” and “Shadow Data” blind spots.
Secure AI Models & Usage: Protect your AI models from tampering and implement safeguards against attacks like prompt injection.
Protect the Data: Enforce strong access controls, encrypt all sensitive data, and continuously monitor data usage for anomalous behavior.
3. Bridge the Gap Between Governance and Security
Security and governance are two sides of the same coin. For an effective AI strategy, they must be deeply integrated. A strong governance policy defines what success looks like, while a strong security posture provides the tools and processes to achieve it. Organizations that align these two functions will be best positioned to harness the power of AI safely and effectively, ultimately lowering their overall risk and the potential cost of a data breach.
The recent joint statement from Microsoft and OpenAI has reaffirmed their long-term AI partnership, as reported by FutureTools News. This commitment to collaboration is expected to drive innovation in the field of artificial intelligence and shape the future of technology. The partnership between Microsoft and OpenAI has been instrumental in developing cutting-edge AI solutions, including the integration of OpenAI’s models with Microsoft’s Azure cloud platform.
Background of the Partnership
The partnership between Microsoft and OpenAI was formed with the goal of advancing the field of artificial intelligence and developing new technologies that can benefit society. The collaboration has led to significant breakthroughs in areas such as natural language processing and computer vision. The joint statement from Microsoft and OpenAI emphasizes their shared commitment to responsible AI development and the importance of ensuring that AI systems are aligned with human values.
Key Areas of Focus
The partnership between Microsoft and OpenAI is focused on several key areas, including the development of large language models and the integration of AI with other technologies such as GitHub and AWS. The goal is to create AI systems that can learn and improve over time, and that can be used to solve complex problems in areas such as healthcare and education. As stated by a Microsoft spokesperson,
The partnership between Microsoft and OpenAI is a key part of our strategy to advance the field of artificial intelligence and to develop new technologies that can benefit society. We are committed to working together to ensure that AI systems are developed and used in ways that are responsible and aligned with human values.
Future Directions
The joint statement from Microsoft and OpenAI also highlights their plans for future collaboration and innovation. The partners are expected to continue working together to develop new AI technologies and to explore new applications for AI in areas such as cybersecurity and sustainability. The partnership is also expected to drive innovation in the field of AI ethics and to promote the development of AI systems that are transparent, explainable, and fair. As the field of artificial intelligence continues to evolve, the partnership between Microsoft and OpenAI is likely to play a significant role in shaping the future of technology and ensuring that AI systems are developed and used in ways that benefit society.
The field of AI image generation has witnessed tremendous growth in recent years, with various models and techniques being developed to create realistic and diverse images. As reported by The Rundown AI, the latest advancements in this field have led to the emergence of a new top banana in AI image generation. This article will delve into the details of this new development and explore its potential applications.
Introduction to AI Image Generation
AI image generation refers to the use of artificial intelligence algorithms to create images that are similar to those produced by humans. This technology has numerous applications, including computer vision, robotics, and gaming. The process of AI image generation involves training a model on a large dataset of images, which enables it to learn patterns and features that can be used to generate new images.
The New Top Banana in AI Image Generation
According to The Rundown AI, the new top banana in AI image generation is a model developed by Anthropic, a leading AI research organization. This model has demonstrated exceptional capabilities in generating high-quality images that are comparable to those produced by humans. The model’s architecture is based on a combination of deep learning and machine learning techniques, which enables it to learn complex patterns and features from large datasets.
The new top banana in AI image generation has the potential to revolutionize the field of computer vision and enable the development of more sophisticated AI-powered applications.
Applications of AI Image Generation
The applications of AI image generation are diverse and widespread. Some of the most significant applications include computer vision, robotics, gaming, and healthcare. In computer vision, AI image generation can be used to create synthetic images that can be used to train models for object detection, segmentation, and recognition. In robotics, AI image generation can be used to create realistic simulations of environments, which can be used to train robots to navigate and interact with their surroundings.
Creating an AI Assistant with its Own Phone Number
In addition to AI image generation, The Rundown AI also provides information on how to create an AI assistant with its own phone number. This can be achieved using a combination of natural language processing and machine learning techniques, which enable the AI assistant to understand and respond to voice commands. The AI assistant can be integrated with various platforms, including GitHub, to enable seamless communication and interaction.
Conclusion
In conclusion, the new top banana in AI image generation has the potential to revolutionize the field of computer vision and enable the development of more sophisticated AI-powered applications. The applications of AI image generation are diverse and widespread, and the technology has the potential to transform various industries, including healthcare, gaming, and robotics. As reported by The Rundown AI, the future of AI image generation looks promising, and we can expect to see significant advancements in this field in the coming years.
The concept of intelligence ownership has been gaining traction in recent years, and for good reason. As Cisco has demonstrated, owning intelligence rather than renting it can be a game-changer for enterprises looking to scale their operations securely. According to a recent article by The Rundown AI, Cisco’s strategy to scale agents securely and reshape enterprise workflows is a prime example of this shift.
The Importance of Intelligence Ownership
Owning intelligence means having control over the data, algorithms, and insights that drive business decisions. This is particularly crucial in today’s fast-paced, data-driven world, where artificial intelligence and machine learning are becoming increasingly prevalent. By owning their intelligence, enterprises can ensure that their systems are secure, transparent, and aligned with their overall goals.
Scaling Agents Securely with Cisco
Cisco’s approach to scaling agents securely is centered around the idea of intelligence ownership. By developing and owning their own AI-powered agents, Cisco is able to ensure that their systems are secure, efficient, and tailored to their specific needs. This approach has allowed Cisco to reshape their enterprise workflows and improve overall productivity. As AWS and other cloud providers continue to evolve, the importance of owning intelligence will only continue to grow.
Cisco’s strategy is a great example of how owning intelligence can help enterprises scale their operations securely and efficiently. By taking control of their data and algorithms, companies can ensure that their systems are aligned with their overall goals and values.
The Benefits of Owning Intelligence
So why should enterprises prioritize intelligence ownership? The benefits are numerous. For one, owning intelligence provides a level of control and transparency that is difficult to achieve with rented intelligence. It also allows enterprises to develop systems that are tailored to their specific needs and goals, rather than relying on generic, off-the-shelf solutions. Additionally, owning intelligence can help enterprises to improve their overall security posture, as they are able to develop and implement their own security protocols and measures.
In contrast, rented intelligence can be limiting and inflexible. When enterprises rely on rented intelligence, they are often at the mercy of the provider, with limited control over the data, algorithms, and insights that drive their business decisions. This can lead to a lack of transparency, security risks, and a general sense of disempowerment.
Real-World Applications
So what does intelligence ownership look like in practice? One example is the development of custom GitHub repositories, which allow enterprises to own and control their code and data. Another example is the use of Azure and other cloud platforms to develop and deploy custom AI-powered solutions. By taking control of their intelligence, enterprises can develop systems that are tailored to their specific needs and goals, and that provide a level of security, transparency, and efficiency that is difficult to achieve with rented intelligence.