Not long ago, OpenAI unveiled a feature that might seem like just another handy update but is, in fact, a seismic shift in the world of artificial intelligence. The new ChatGPT Agent isn’t merely a consumer-facing tool; it represents a fundamentally new platform for automation with significant, long-term ramifications for the entire AI automation agency model. We’re not just seeing a new competitor on the block; we’re witnessing the birth of a new automation landscape—one that could redefine digital labor as we know it.
In this article, we’ll break down exactly what makes this development so significant, how it reshapes the AI ecosystem, and what your agency needs to know to stay ahead of the curve and capitalize on this incredible opportunity.
What Makes the ChatGPT Agent a Revolutionary Leap?
The core reason the ChatGPT Agent is so monumental is that it’s the first true “digital worker.” For the first time, we have a widely accessible software that can operate a computer one-for-one like a human, potentially replacing a person in a specific task or even an entire role down the line. This is a profound departure from the AI agents we’ve built until now.
Think of the difference between a special-purpose machine and a general-purpose robot. Until now, AI agents have been like dishwashers—highly engineered machines built for a very specific purpose. They are fantastic at one thing (e.g., washing dishes or running a specific API-based workflow) but are inflexible outside of that defined task.
The new computer-operating agent, however, is like a general-purpose humanoid robot. It’s the software version of a robot like Tesla’s Optimus. Just as a humanoid robot can be programmed to wash dishes, clean the floor, or assemble furniture, the ChatGPT Agent can be instructed to perform a vast range of digital tasks by simply interacting with a computer’s interface, just as a human would.
Specialized agents are like dishwashers, while the new ChatGPT Agent acts like a general-purpose robot for digital tasks.
This fundamentally changes how we approach automation. Instead of relying solely on complex, pre-built API integrations for every single software, we now have an agent that can see the screen, move the mouse, and type on the keyboard, opening up automation possibilities for virtually any application.
The New AI Automation Landscape Explained
This shift validates a long-standing debate in the AI community: would advanced agents be built on a massive web of APIs, or would they use vision models to navigate the digital world? With this release, it’s clear that computer vision-based operation has taken a massive leap forward.
To understand where this new technology fits, let’s map out the modern AI automation landscape. It can be broken down into three core pillars: Automations, AI Tools, and AI Agents.
AI Agents themselves are now splitting into distinct categories:
Human-Operated (Specialized): These are “co-pilots” or “dishwashers”—agents built for a specific role and operated by a human. They assist with tasks like generating a pre-call sales report or updating a CRM, but they are highly specialized and rely on a human to trigger them.
Automated: These are agents embedded within a larger workflow, often triggered by an event (like a new form submission) rather than direct human interaction. They perform a sequence of pre-defined actions.
Computer-Operating (Generalist): This is the new frontier. These are the “humanoid robots” that can perform a wide variety of tasks by navigating digital interfaces. They can be human-operated (like the current ChatGPT Agent) or fully automated in the future.
To learn more about building traditional workflows, check out our guides in the AI How-To’s & Tricks category.
When to Use a Generalist vs. a Specialist Agent
Understanding this new landscape is crucial for AI automation agencies advising their clients. The key is knowing when to build a highly-structured “dishwasher” versus when to deploy a flexible “humanoid robot.”
Let’s look at a few common business tasks:
Competitor Research: A specialist agent wins here. A dedicated research agent or feature that is highly structured for data gathering will be faster and more reliable than a generalist agent browsing the web.
Simple Lead Generation: Again, a specialist wins. A targeted, automated workflow designed specifically for scraping data from known sources is more efficient and scalable for high-volume outreach.
Creating Slideshows: The generalist shines. An agent that can combine research, data analysis, and file generation in one fluid motion is incredibly powerful. It can pull data from a spreadsheet, analyze it, and then build a PowerPoint presentation without needing three separate specialized tools.
Managing a Cold Email Campaign: The generalist is the clear winner. This task involves navigating multiple web apps—Gmail, a CRM, a spreadsheet—often without complex API integrations available. A computer-operating agent can handle this boring, repetitive browser-based admin work perfectly.
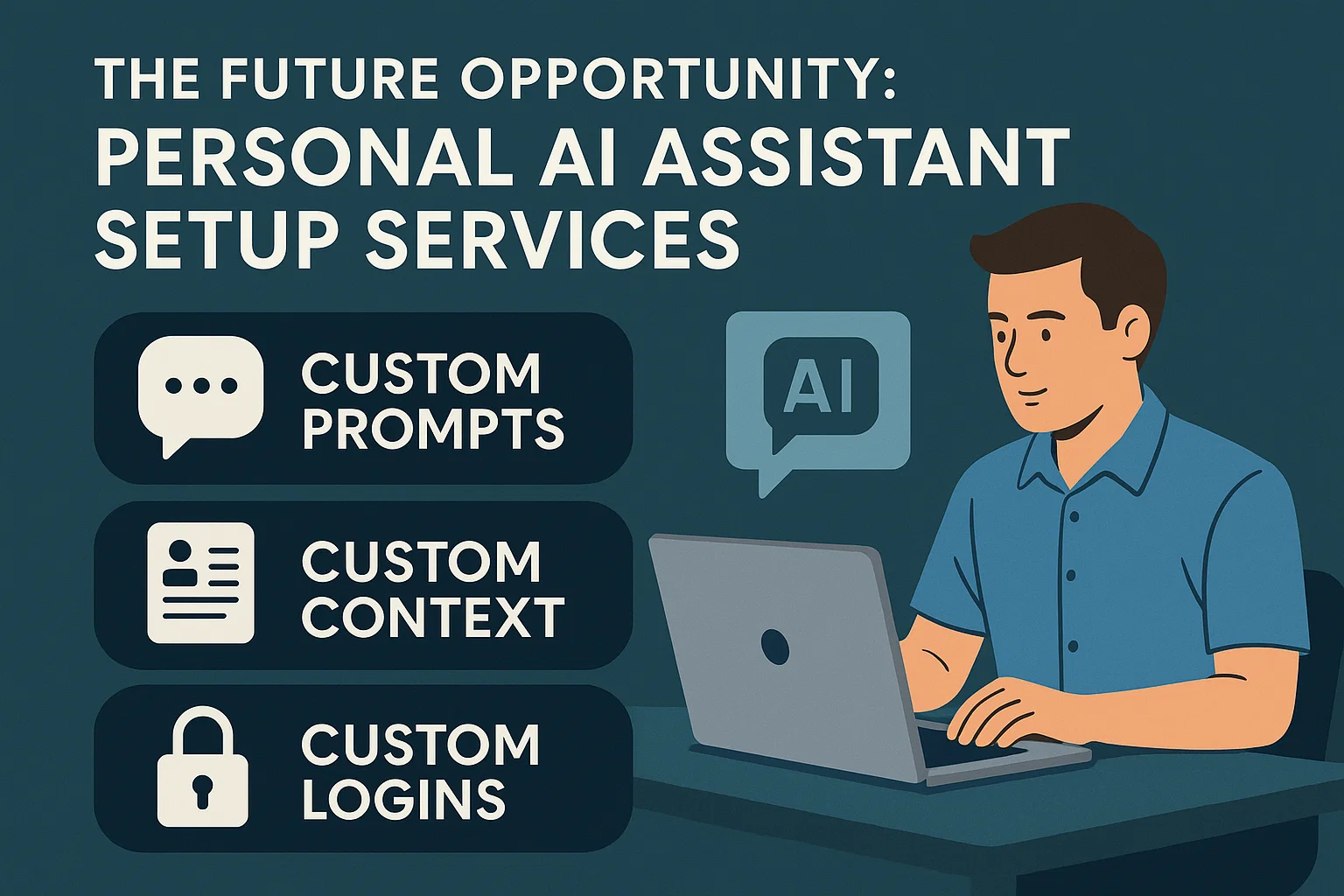
The Future Opportunity: Personal AI Assistant Setup Services
While the consumer version of the ChatGPT Agent is available now, a business or API version is inevitable. This will unlock the true opportunity for AI agencies: creating and configuring personalized agents for every single employee in a company.
Imagine a service where your agency audits an employee’s daily tasks and then builds a custom agent for them. For “Lindy the Marketer,” you could create an agent with:
Custom Prompts: Engineered to match her tone of voice and marketing goals.
Custom Context: Connected to the company’s Notion or knowledge base.
Custom Logins: Pre-authorized to access her Instantly, LinkedIn, and Gmail accounts.
This service—essentially setting up a personal AI assistant for every team member—is where the puck is going. By understanding the distinction between specialized workflows and generalist agents, you can position your agency to not only build powerful automations but also to fundamentally enhance the productivity of entire workforces. This is the new frontier of AI automation, and the agencies that prepare for it now will be the ones who lead the way.
To stay updated, keep an eye on the official OpenAI Blog for their business-level announcements.
The recent joint statement from Microsoft and OpenAI has reaffirmed their long-term AI partnership, as reported by FutureTools News. This commitment to collaboration is expected to drive innovation in the field of artificial intelligence and shape the future of technology. The partnership between Microsoft and OpenAI has been instrumental in developing cutting-edge AI solutions, including the integration of OpenAI’s models with Microsoft’s Azure cloud platform.
Background of the Partnership
The partnership between Microsoft and OpenAI was formed with the goal of advancing the field of artificial intelligence and developing new technologies that can benefit society. The collaboration has led to significant breakthroughs in areas such as natural language processing and computer vision. The joint statement from Microsoft and OpenAI emphasizes their shared commitment to responsible AI development and the importance of ensuring that AI systems are aligned with human values.
Key Areas of Focus
The partnership between Microsoft and OpenAI is focused on several key areas, including the development of large language models and the integration of AI with other technologies such as GitHub and AWS. The goal is to create AI systems that can learn and improve over time, and that can be used to solve complex problems in areas such as healthcare and education. As stated by a Microsoft spokesperson,
The partnership between Microsoft and OpenAI is a key part of our strategy to advance the field of artificial intelligence and to develop new technologies that can benefit society. We are committed to working together to ensure that AI systems are developed and used in ways that are responsible and aligned with human values.
Future Directions
The joint statement from Microsoft and OpenAI also highlights their plans for future collaboration and innovation. The partners are expected to continue working together to develop new AI technologies and to explore new applications for AI in areas such as cybersecurity and sustainability. The partnership is also expected to drive innovation in the field of AI ethics and to promote the development of AI systems that are transparent, explainable, and fair. As the field of artificial intelligence continues to evolve, the partnership between Microsoft and OpenAI is likely to play a significant role in shaping the future of technology and ensuring that AI systems are developed and used in ways that benefit society.
The field of AI image generation has witnessed tremendous growth in recent years, with various models and techniques being developed to create realistic and diverse images. As reported by The Rundown AI, the latest advancements in this field have led to the emergence of a new top banana in AI image generation. This article will delve into the details of this new development and explore its potential applications.
Introduction to AI Image Generation
AI image generation refers to the use of artificial intelligence algorithms to create images that are similar to those produced by humans. This technology has numerous applications, including computer vision, robotics, and gaming. The process of AI image generation involves training a model on a large dataset of images, which enables it to learn patterns and features that can be used to generate new images.
The New Top Banana in AI Image Generation
According to The Rundown AI, the new top banana in AI image generation is a model developed by Anthropic, a leading AI research organization. This model has demonstrated exceptional capabilities in generating high-quality images that are comparable to those produced by humans. The model’s architecture is based on a combination of deep learning and machine learning techniques, which enables it to learn complex patterns and features from large datasets.
The new top banana in AI image generation has the potential to revolutionize the field of computer vision and enable the development of more sophisticated AI-powered applications.
Applications of AI Image Generation
The applications of AI image generation are diverse and widespread. Some of the most significant applications include computer vision, robotics, gaming, and healthcare. In computer vision, AI image generation can be used to create synthetic images that can be used to train models for object detection, segmentation, and recognition. In robotics, AI image generation can be used to create realistic simulations of environments, which can be used to train robots to navigate and interact with their surroundings.
Creating an AI Assistant with its Own Phone Number
In addition to AI image generation, The Rundown AI also provides information on how to create an AI assistant with its own phone number. This can be achieved using a combination of natural language processing and machine learning techniques, which enable the AI assistant to understand and respond to voice commands. The AI assistant can be integrated with various platforms, including GitHub, to enable seamless communication and interaction.
Conclusion
In conclusion, the new top banana in AI image generation has the potential to revolutionize the field of computer vision and enable the development of more sophisticated AI-powered applications. The applications of AI image generation are diverse and widespread, and the technology has the potential to transform various industries, including healthcare, gaming, and robotics. As reported by The Rundown AI, the future of AI image generation looks promising, and we can expect to see significant advancements in this field in the coming years.
The concept of intelligence ownership has been gaining traction in recent years, and for good reason. As Cisco has demonstrated, owning intelligence rather than renting it can be a game-changer for enterprises looking to scale their operations securely. According to a recent article by The Rundown AI, Cisco’s strategy to scale agents securely and reshape enterprise workflows is a prime example of this shift.
The Importance of Intelligence Ownership
Owning intelligence means having control over the data, algorithms, and insights that drive business decisions. This is particularly crucial in today’s fast-paced, data-driven world, where artificial intelligence and machine learning are becoming increasingly prevalent. By owning their intelligence, enterprises can ensure that their systems are secure, transparent, and aligned with their overall goals.
Scaling Agents Securely with Cisco
Cisco’s approach to scaling agents securely is centered around the idea of intelligence ownership. By developing and owning their own AI-powered agents, Cisco is able to ensure that their systems are secure, efficient, and tailored to their specific needs. This approach has allowed Cisco to reshape their enterprise workflows and improve overall productivity. As AWS and other cloud providers continue to evolve, the importance of owning intelligence will only continue to grow.
Cisco’s strategy is a great example of how owning intelligence can help enterprises scale their operations securely and efficiently. By taking control of their data and algorithms, companies can ensure that their systems are aligned with their overall goals and values.
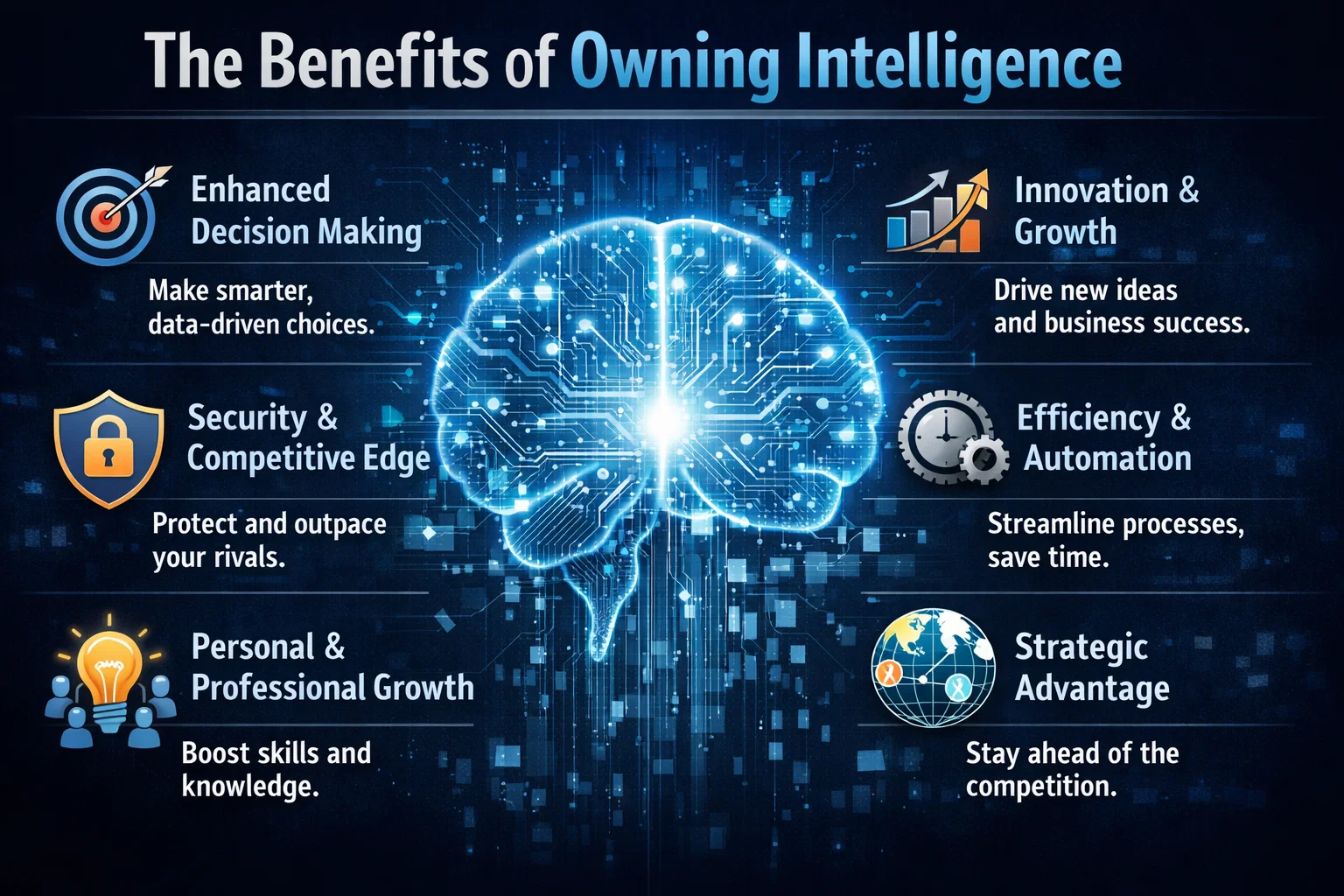
The Benefits of Owning Intelligence
So why should enterprises prioritize intelligence ownership? The benefits are numerous. For one, owning intelligence provides a level of control and transparency that is difficult to achieve with rented intelligence. It also allows enterprises to develop systems that are tailored to their specific needs and goals, rather than relying on generic, off-the-shelf solutions. Additionally, owning intelligence can help enterprises to improve their overall security posture, as they are able to develop and implement their own security protocols and measures.
In contrast, rented intelligence can be limiting and inflexible. When enterprises rely on rented intelligence, they are often at the mercy of the provider, with limited control over the data, algorithms, and insights that drive their business decisions. This can lead to a lack of transparency, security risks, and a general sense of disempowerment.
Real-World Applications
So what does intelligence ownership look like in practice? One example is the development of custom GitHub repositories, which allow enterprises to own and control their code and data. Another example is the use of Azure and other cloud platforms to develop and deploy custom AI-powered solutions. By taking control of their intelligence, enterprises can develop systems that are tailored to their specific needs and goals, and that provide a level of security, transparency, and efficiency that is difficult to achieve with rented intelligence.