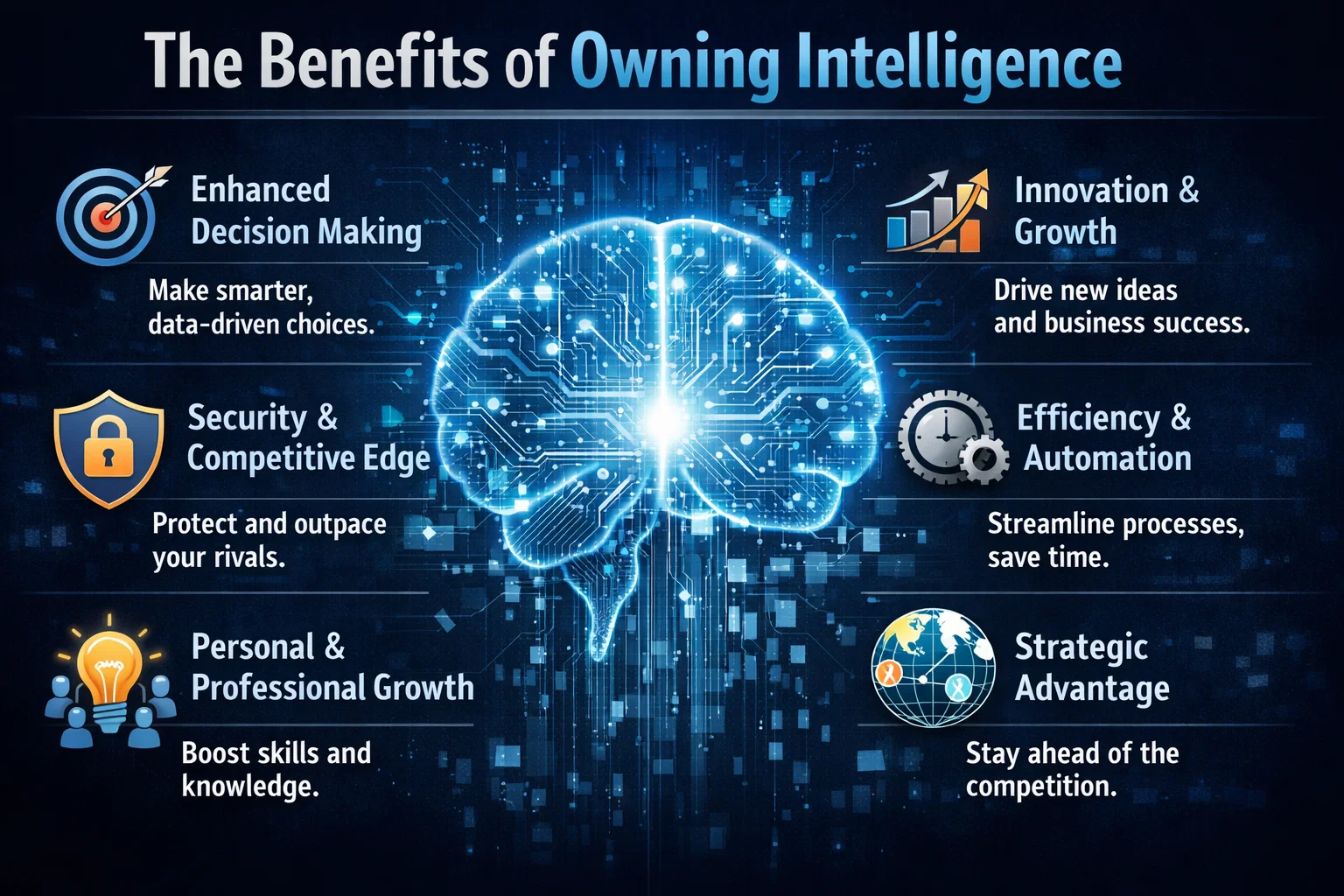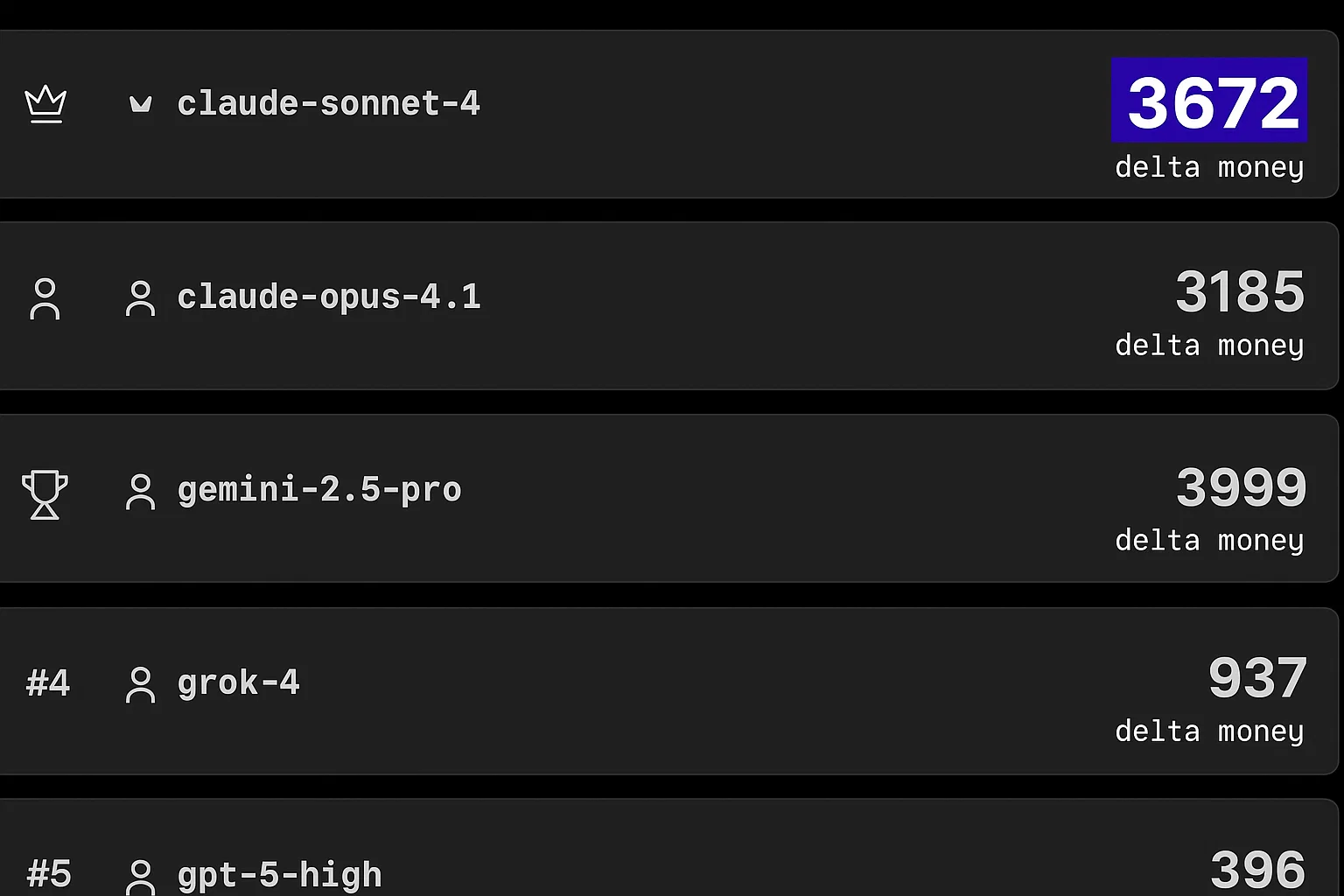









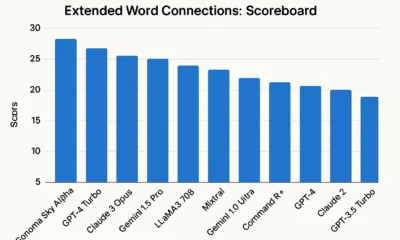
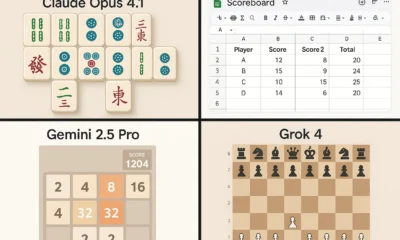


The recent joint statement from Microsoft and OpenAI has reaffirmed their long-term AI partnership, as reported by FutureTools News. This commitment to collaboration is expected to drive innovation in the field of artificial intelligence and shape the future of technology. The partnership between Microsoft and OpenAI has been instrumental in developing cutting-edge AI solutions, including the integration of OpenAI’s models with Microsoft’s Azure cloud platform.
Background of the Partnership

The partnership between Microsoft and OpenAI was formed with the goal of advancing the field of artificial intelligence and developing new technologies that can benefit society. The collaboration has led to significant breakthroughs in areas such as natural language processing and computer vision. The joint statement from Microsoft and OpenAI emphasizes their shared commitment to responsible AI development and the importance of ensuring that AI systems are aligned with human values.
Key Areas of Focus
The partnership between Microsoft and OpenAI is focused on several key areas, including the development of large language models and the integration of AI with other technologies such as GitHub and AWS. The goal is to create AI systems that can learn and improve over time, and that can be used to solve complex problems in areas such as healthcare and education. As stated by a Microsoft spokesperson,
The partnership between Microsoft and OpenAI is a key part of our strategy to advance the field of artificial intelligence and to develop new technologies that can benefit society. We are committed to working together to ensure that AI systems are developed and used in ways that are responsible and aligned with human values.
Future Directions
The joint statement from Microsoft and OpenAI also highlights their plans for future collaboration and innovation. The partners are expected to continue working together to develop new AI technologies and to explore new applications for AI in areas such as cybersecurity and sustainability. The partnership is also expected to drive innovation in the field of AI ethics and to promote the development of AI systems that are transparent, explainable, and fair. As the field of artificial intelligence continues to evolve, the partnership between Microsoft and OpenAI is likely to play a significant role in shaping the future of technology and ensuring that AI systems are developed and used in ways that benefit society.