
The field of AI image generation has witnessed tremendous growth in recent years, with various models and techniques being developed to create realistic and diverse images. As reported by The Rundown AI, the latest advancements in this field have led to the emergence of a new top banana in AI image generation. This article will delve into the details of this new development and explore its potential applications.
Introduction to AI Image Generation
AI image generation refers to the use of artificial intelligence algorithms to create images that are similar to those produced by humans. This technology has numerous applications, including computer vision, robotics, and gaming. The process of AI image generation involves training a model on a large dataset of images, which enables it to learn patterns and features that can be used to generate new images.
The New Top Banana in AI Image Generation

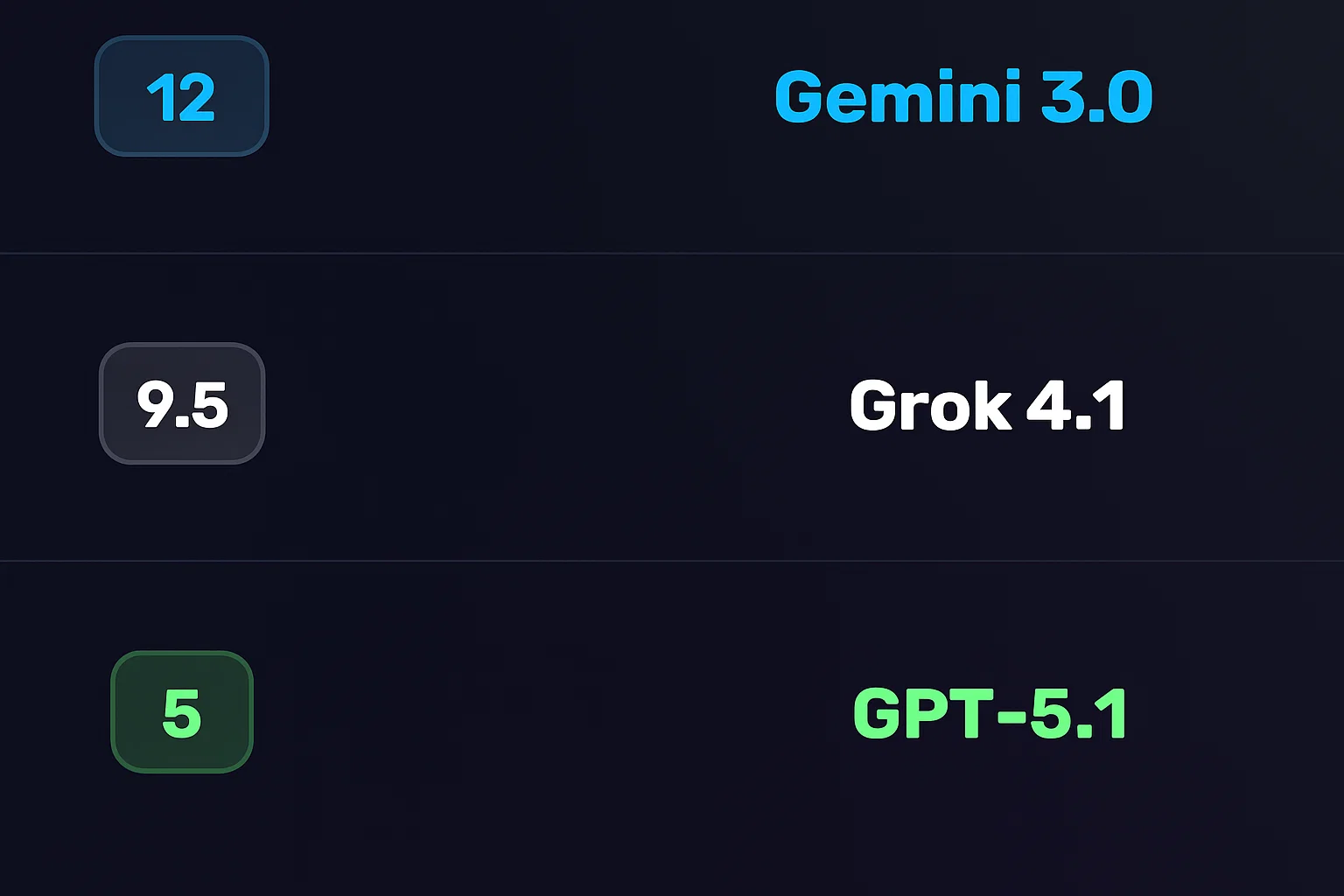
According to The Rundown AI, the new top banana in AI image generation is a model developed by Anthropic, a leading AI research organization. This model has demonstrated exceptional capabilities in generating high-quality images that are comparable to those produced by humans. The model’s architecture is based on a combination of deep learning and machine learning techniques, which enables it to learn complex patterns and features from large datasets.
The new top banana in AI image generation has the potential to revolutionize the field of computer vision and enable the development of more sophisticated AI-powered applications.
Applications of AI Image Generation

The applications of AI image generation are diverse and widespread. Some of the most significant applications include computer vision, robotics, gaming, and healthcare. In computer vision, AI image generation can be used to create synthetic images that can be used to train models for object detection, segmentation, and recognition. In robotics, AI image generation can be used to create realistic simulations of environments, which can be used to train robots to navigate and interact with their surroundings.
Creating an AI Assistant with its Own Phone Number
In addition to AI image generation, The Rundown AI also provides information on how to create an AI assistant with its own phone number. This can be achieved using a combination of natural language processing and machine learning techniques, which enable the AI assistant to understand and respond to voice commands. The AI assistant can be integrated with various platforms, including GitHub, to enable seamless communication and interaction.
Conclusion
In conclusion, the new top banana in AI image generation has the potential to revolutionize the field of computer vision and enable the development of more sophisticated AI-powered applications. The applications of AI image generation are diverse and widespread, and the technology has the potential to transform various industries, including healthcare, gaming, and robotics. As reported by The Rundown AI, the future of AI image generation looks promising, and we can expect to see significant advancements in this field in the coming years.