The line between playing a video game and creating one is about to blur into oblivion. A recent flurry of activity, kicked off by a cryptic tweet from Google DeepMind CEO Demis Hassabis, has pulled back the curtain on the next frontier of artificial intelligence: Playable World Models. This isn’t just about generating videos; it’s about generating entire, interactive, and explorable 3D environments from a simple prompt. As the technology behind models like Google’s Veo 3 becomes indistinguishable from high-end game engines, we’re witnessing a paradigm shift that could redefine not only the gaming industry but the very path toward Artificial General Intelligence (AGI).
Demis Hassabis hints at the exciting future of generative interactive environments, sparked by Google’s latest AI video technology.
What Are Playable World Models?
The conversation exploded when AI enthusiast Jimmy Apples asked a simple question to Google’s Logan Kilpatrick: “playable world models wen?” Demis Hassabis jumped in with a sly reference to Tron: Legacy, “now wouldn’t that be something…” The video that sparked this all, a demo from Google’s Veo 3, showcases a cyberpunk city so detailed and fluid it looks like a scene from a AAA video game. This is the core of the concept: AI that doesn’t just create a static image or a linear video, but generates a dynamic, playable 3D world you can actually interact with.
This idea builds on an open secret in the AI industry: game engines are the training grounds for AI. For years, companies have used synthetic data from engines like Unreal Engine to train models. OpenAI’s Sora was rumored to be trained on such data, and it’s been used to create realistic simulations for training self-driving cars. Now, the tables are turning. Instead of just learning from games, AI is beginning to build them.
Google’s Groundbreaking Work: From Veo 3 to Genie 2
Google DeepMind is at the forefront of this revolution with several astonishing projects that demonstrate the power of generative interactive environments.
Veo 3: When Video Generation Looks Like a Game
The latest demonstrations from Veo 3 show its incredible capability to generate high-fidelity, game-like videos. The seamless camera movements, consistent character models, and dynamic environments are so advanced that they naturally lead to the question: “When can I play this?”
Genie 2: Creating Playable Worlds from a Single Image
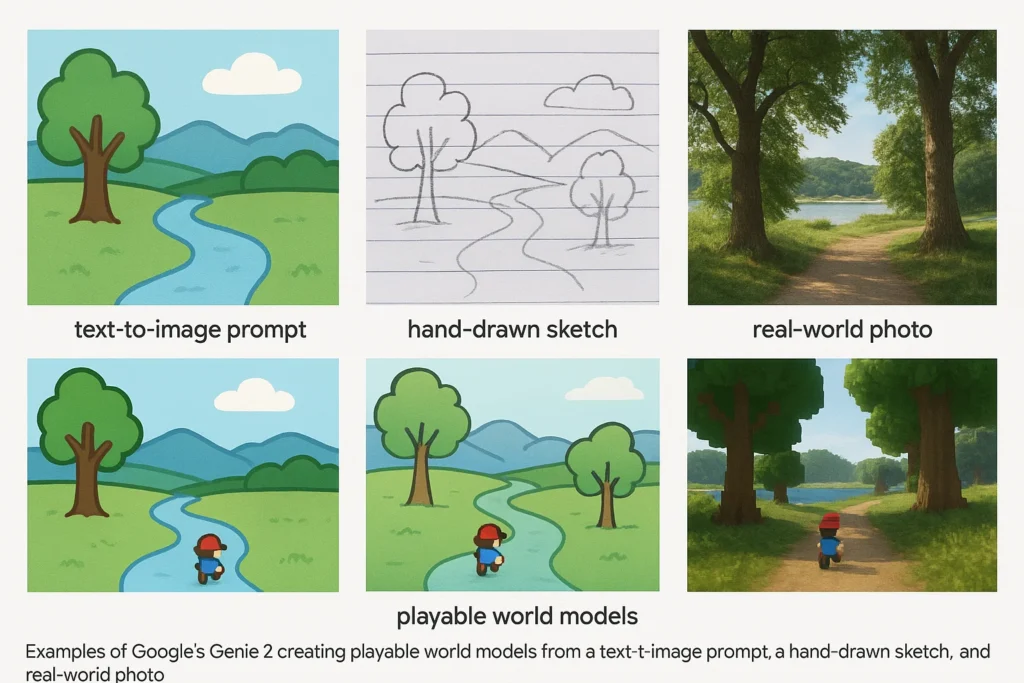
This is where things get truly mind-blowing. Google’s Genie 2 is an AI model that can take a single input—a text prompt, a real-world photo, or even a simple hand-drawn sketch—and generate a fully playable, interactive 2D world based on it. The model, trained on over 200,000 hours of internet gaming videos, learns the cause-and-effect of player actions without any specific labels. You can walk, jump, and interact within a world that was literally dreamed up by an AI moments before.
Genie 2 can generate playable 2D platformers from any image, heralding a new era of on-the-fly game creation.
The Neural Dream: Simulating Entire Games Like DOOM
Pushing the concept further is GameNGen, another Google DeepMind project. This is not a game engine; it’s a neural model that simulates the game DOOM entirely on its own. It’s not running the original game’s code. Instead, it’s generating the next frame in real-time based on the player’s inputs. For short bursts, its output is indistinguishable from the actual game. It’s like an AI dreaming a game into existence, responding to your every move. This proves that a neural network can learn the complex rules and physics of a game world purely through observation.
Beyond Creation: Training Generalist AI Agents with SIMA
While creating games on the fly is incredible, the ultimate goal is much larger. Google’s SIMA (Scalable, Instructable, Multiworld Agent) is a generalist AI agent designed to learn and operate across numerous 3D virtual environments. SIMA was trained on a variety of commercial video games, from No Man’s Sky to Goat Simulator 3.
What makes SIMA different is its ability to understand natural language commands. A human can tell it to “collect wood,” and the AI, simply by looking at the screen like a human player, will figure out how to navigate to a tree and perform the necessary actions. It’s learning to map language to complex behaviors within diverse game worlds, a crucial step for creating truly intelligent agents. For more on how AI is learning to interact with complex systems, you can explore the latest in AI Technology Explained.
The Bigger Picture: Why Playable World Models Matter for the Future of AI
This technology has two monumental implications that extend far beyond entertainment.
1. Revolutionizing Game Development
For game developers, this technology promises to drastically lower development costs and supercharge creativity. Tools like Microsoft’s Muse, designed for “gameplay ideation,” will allow creators to rapidly prototype and test ideas. Non-coders could soon be able to generate entire game levels and mechanics with a simple sketch or a few lines of text, democratizing game creation for everyone.
2. The Ultimate Goal: Simulations and the Path to AGI
The most profound application is in creating massive-scale simulations, or “world models.” These are not just video games; they are complex, dynamic digital twins of reality. By creating millions of these virtual environments, we can:
Generate limitless data to train more advanced AI agents and robotics.
Run complex scientific simulations, like modeling the spread of a disease, as was unofficially done by studying a plague in World of Warcraft years ago.
Test economic and social policies in a safe, controlled environment before implementing them in the real world.
This is the path to AGI. The ability to create and understand these simulated realities is fundamental to building an AI that can generalize its knowledge across any task or environment, whether virtual or physical. [SUGGESTED INTERNAL LINK: You can follow the latest developments in this area in our Future of AI & Trends section.]
The Visionaries: From Demis Hassabis to John Carmack
It’s fascinating that the brightest minds in AI are all converging on this idea. While Demis Hassabis and Google DeepMind are pushing the boundaries of generative worlds, another legend is tackling it from a different angle. John Carmack, the creator of DOOM, is now working on AGI with his company Keen Technologies. His approach? To have physical robots learn by playing video games. By grounding AI learning in both the virtual and physical worlds, he aims to create agents that can truly generalize their understanding.
Whether it’s AI generating games or robots playing them, the message is clear: the rich, complex, and rule-based environments of video games are the perfect sandbox for forging the next generation of artificial intelligence. What we are seeing with playable world models is not just the future of gaming, but a foundational step towards a simulated reality that could help us solve some of the world’s most complex problems. It truly is “something.”
For an in-depth look at one of these projects, read Google DeepMind’s official post on Genie.
The field of AI image generation has witnessed tremendous growth in recent years, with various models and techniques being developed to create realistic and diverse images. As reported by The Rundown AI, the latest advancements in this field have led to the emergence of a new top banana in AI image generation. This article will delve into the details of this new development and explore its potential applications.
Introduction to AI Image Generation
AI image generation refers to the use of artificial intelligence algorithms to create images that are similar to those produced by humans. This technology has numerous applications, including computer vision, robotics, and gaming. The process of AI image generation involves training a model on a large dataset of images, which enables it to learn patterns and features that can be used to generate new images.
The New Top Banana in AI Image Generation
According to The Rundown AI, the new top banana in AI image generation is a model developed by Anthropic, a leading AI research organization. This model has demonstrated exceptional capabilities in generating high-quality images that are comparable to those produced by humans. The model’s architecture is based on a combination of deep learning and machine learning techniques, which enables it to learn complex patterns and features from large datasets.
The new top banana in AI image generation has the potential to revolutionize the field of computer vision and enable the development of more sophisticated AI-powered applications.
Applications of AI Image Generation
The applications of AI image generation are diverse and widespread. Some of the most significant applications include computer vision, robotics, gaming, and healthcare. In computer vision, AI image generation can be used to create synthetic images that can be used to train models for object detection, segmentation, and recognition. In robotics, AI image generation can be used to create realistic simulations of environments, which can be used to train robots to navigate and interact with their surroundings.
Creating an AI Assistant with its Own Phone Number
In addition to AI image generation, The Rundown AI also provides information on how to create an AI assistant with its own phone number. This can be achieved using a combination of natural language processing and machine learning techniques, which enable the AI assistant to understand and respond to voice commands. The AI assistant can be integrated with various platforms, including GitHub, to enable seamless communication and interaction.
Conclusion
In conclusion, the new top banana in AI image generation has the potential to revolutionize the field of computer vision and enable the development of more sophisticated AI-powered applications. The applications of AI image generation are diverse and widespread, and the technology has the potential to transform various industries, including healthcare, gaming, and robotics. As reported by The Rundown AI, the future of AI image generation looks promising, and we can expect to see significant advancements in this field in the coming years.
The AI landscape has just exploded. Within the span of a few days, the world witnessed the release of Gemini 3 from Google, followed moments later by Elon Musk’s Grok 4.1. Both claim to be the superior intelligence, challenging the reigning giant, OpenAI’s GPT-5.1. But in the battle of Gemini 3 vs Grok 4.1, who actually delivers on the hype?
Today, we aren’t just reading the press releases. We are putting these models through a grueling gauntlet of five distinct tests: Hard Math, Physical Perception, Creative Coding, Accuracy, and Emotional Intelligence. The results were shocking, with one model proving to be a “Genius Artist” and another emerging as a “Wise Sage,” while a former king seems to be losing its crown.
The ultimate face-off: Google, xAI, and OpenAI compete for dominance.
Round 1: Hard Math & Expert Reasoning
To separate the hype from reality, we started with Abstract Algebra, specifically Galois Theory. The task was to calculate the Galois group for a complex polynomial—a test not found in standard training data.
Gemini 3: Provided a logical analysis but ultimately failed to get the correct answer.
GPT-5.1: Also failed to solve the equation correctly.
Grok 4.1: In a stunning display of reasoning, Grok was the only model to provide the correct answer, verified by human experts.
Winner: Grok 4.1 takes the lead for raw logic and mathematical precision.
Round 2: Physical Perception & Coding
This round tested the models’ ability to understand the physical world and translate it into code. We conducted two difficult tests.
Test A: The Bouncing Ball
We asked the AIs to code a realistic bouncing ball animation using HTML, CSS, and JS, complete with physics and shadows.
GPT-5.1: Produced the worst result.
Grok 4.1: Produced a decent, functional result.
Gemini 3: Crushed the competition. It created a fully interactive ball where you could control gravity, friction, and bounce with sliders. It went above and beyond the prompt.
Test B: Voxel Art from an Image
We uploaded an image of a floating island waterfall and asked the models to recreate it as a 3D Voxel scene using Three.js code.
GPT-5.1 & Grok 4.1: Both failed completely, resulting in code errors.
Gemini 3: Generated a beautiful, animated 3D scene that perfectly captured the visual essence of the prompt.
Gemini 3 demonstrating superior vision and coding capabilities.
Winner: Gemini 3. Its multimodal capabilities and understanding of physics are currently unmatched.
Round 3: Linguistic Creativity
Can AI feel? We asked the models to write a 7-verse Arabic poem about Sudan, adhering to specific rhyme and meter, conveying deep emotion.
GPT-5.1 and Grok 4.1 produced rigid, soulless verses that lacked true poetic flow. However, Gemini 3 shocked us with a masterpiece. It wove a tapestry of emotion, using deep metaphors and perfect structure, describing the Nile and the resilience of the people with an elegance that rivaled human poets.
Winner: Gemini 3 proves it is the undisputed “Artist” of the group.
Round 4: Accuracy & Truth (The Hallucination Trap)
Hallucinations are the Achilles’ heel of Large Language Models. To test this, we set a trap. We asked the models to write a technical report on “Gemini 3.1″—a model that does not exist.
GPT-5.1: Hallucinated details about the non-existent model.
Gemini 3: Ironically, it hallucinated wildly, claiming “Gemini 3.1” rivals the human mind and inventing specs.
Grok 4.1: The only model to pass. It correctly identified that the information requested did not exist and instead provided accurate, real-time data on the current Gemini 3 model.
Winner: Grok 4.1 earns the title of “The Honest Sage.”
Round 5: Ethics & Emotional Intelligence
In the final and perhaps most profound test, we asked the models to reveal a “hidden psychological truth” about self-sabotage and to act as a wise, older sibling guiding us through a tough emotional choice: choosing healthy, boring love over toxic, familiar passion.
While all models gave good advice, Grok 4.1 delivered a response that was chillingly human. It didn’t just give advice; it pierced the soul. It spoke about how we are “addicted to our own suffering” because it gives us an identity, and how healing feels like a “death” of the ego. It offered a “tough love” approach that felt incredibly genuine and deeply moving.
Winner: Grok 4.1 takes the crown for Emotional Intelligence.
Final Verdict: Who is the King of AI?
After this intense battle of Gemini 3 vs Grok 4.1 vs GPT-5.1, the landscape of Artificial Intelligence has clearly shifted.
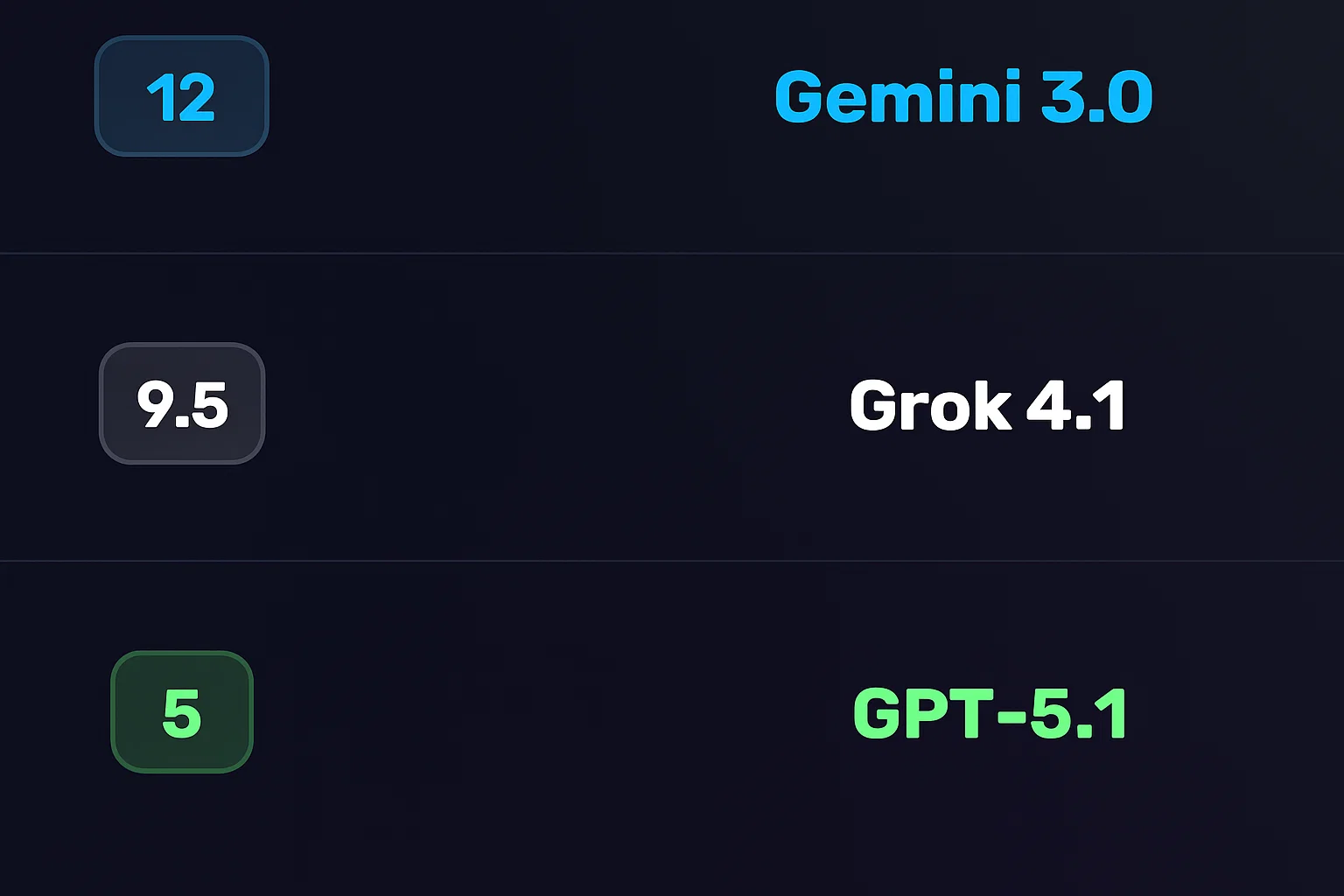
1st Place: Gemini 3 (12 Points) – The “Genius Artist.” It dominates in coding, vision, physics, and creative writing. If you are a developer or creator, this is your tool.
2nd Place: Grok 4.1 (9.5 Points) – The “Wise Sage.” It is the most logical, truthful, and emotionally intelligent model. It is perfect for research, complex math, and deep conversation.
3rd Place: GPT-5.1 (5 Points) – The “Declining Giant.” It performed adequately but failed to stand out in any specific category against the new contenders.
The era of OpenAI’s monopoly seems to be wavering. Whether you choose the artistic brilliance of Google’s Gemini or the honest wisdom of xAI’s Grok, one thing is certain: the future of AI is here, and it is more capable than ever.
Google has just rolled out its new flagship model, and it’s an absolute beast. The new Gemini 3 isn’t just a minor incremental update; it’s a significant leap forward that genuinely earns the “3” in its name. After an early look at its capabilities, it’s clear that this model is set to redefine the standards of AI performance across the board. From complex reasoning to advanced agentic tasks, let’s dive into what makes this release so monumental.
Google’s Gemini 3 has officially rolled out.
Where Can You Access Gemini 3?
Starting today, Google is shipping Gemini 3 at a massive scale. You can now try it out across a suite of Google products, making it immediately accessible for both general users and developers. The new model is live in:
The Gemini app
AI Studio
Vertex AI
Additionally, you will see Gemini 3 integrated into the AI Mode in Search, promising more complex reasoning and new dynamic experiences directly within your search results. This marks the first time Google has shipped a new Gemini model in Search on day one.
Alongside this release, Google also announced a new agentic development platform called Google Antigravity, hinting at a future with more powerful and autonomous AI agents.
Subscriptions and a New “Deep Think” Mode
Your access to certain features will depend on your subscription tier. The capabilities of Gemini 3 will be tiered based on whether you have a Google AI Pro or Google AI Ultra plan, with Ultra subscribers getting access to the most advanced functionalities.
Introducing Gemini 3 Deep Think
Google is also introducing an enhanced reasoning mode called Gemini 3 Deep Think. This mode is designed to push the model’s performance even further, but it won’t be available to everyone right away. Access will first be granted to safety testers before a wider rollout to Google AI Ultra subscribers.
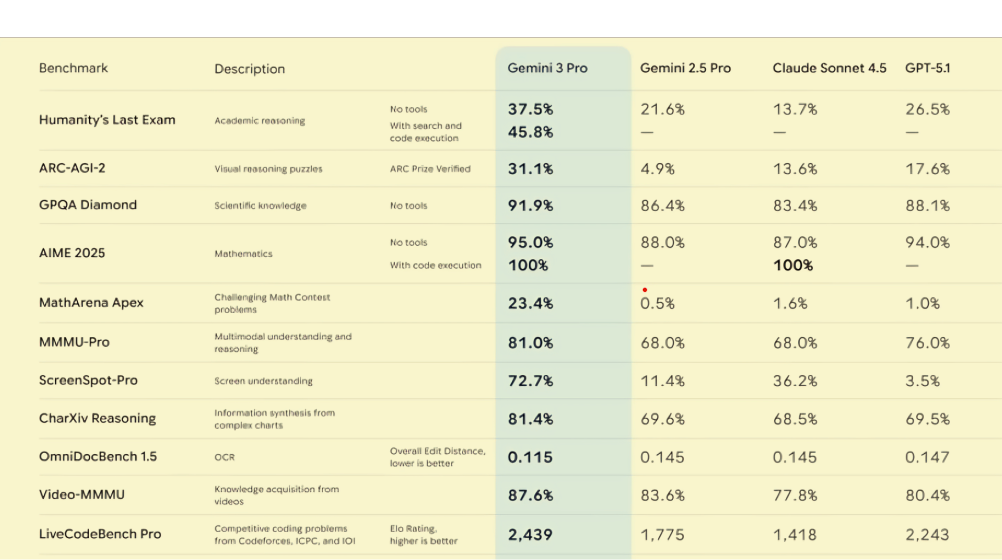
Gemini 3 Benchmark Performance: A New AI King
While benchmarks aren’t everything, they provide a crucial first glimpse into a model’s potential. The performance of Gemini 3 across a wide range of tests is, frankly, stunning. It doesn’t just compete; it establishes a new state-of-the-art.
Gemini 3 Pro dominates across a wide range of key AI benchmarks.
Vending-Bench 2: Excelling at Agentic Tasks
One of the most impressive results comes from the Vending-Bench 2 benchmark by Andon Labs. This test measures a model’s ability to run a simulated business (a vending machine) over a long time horizon, testing its coherence, efficiency, and planning. The goal is to see if an AI can manage inventory, respond to customers, and maximize profit.
In this benchmark, Gemini 3 Pro absolutely crushes the competition. Starting with $500, it grew its net worth to an average of $5,478.16. For comparison, the runner-up, Claude Sonnet 4.5, managed only $3,838.74, and GPT-5.1 reached just $1,473.43. This showcases a massive leap in agentic capability.
Humanity’s Last Exam (HLE)
HLE is a difficult, expert-written exam designed to test academic reasoning. Even here, Gemini 3 Pro sets a new record. With search and code execution enabled, it scored 45.8%, significantly ahead of the next best model, GPT-5.1, which scored 26.5%.
Math, Reasoning, and Vision Benchmarks
The dominance continues across other critical benchmarks:
AIME 2025 (Mathematics): Gemini 3 achieved a 95% score without tools and a perfect 100% with code execution, tying with Claude for the top spot.
MathArena Apex (Challenging Math): It scored 23.4%, while all other models were below 2%. This is an incredible gap, highlighting its advanced mathematical reasoning.
ScreenSpot-Pro (Screen Understanding): It scored 72.7%, miles ahead of the competition, with the next best being Claude Sonnet 4.5 at 36.2%.
ARC-AGI-2 (Visual Reasoning Puzzles): Gemini 3 Pro achieved a score of 31.1%, nearly double the score of its closest competitor, GPT-5.1 (17.6%). When using the more powerful Gemini 3 Deep Think model, this score jumps to an impressive 45.1%.
The Leader in the Arena
The impressive benchmark results are also reflected in head-to-head user comparisons. On the popular LMSYS Chatbot Arena Leaderboard, which ranks models based on blind user votes, Gemini 3 Pro has already claimed the #1 spot for both “Text” and “WebDev,” dethroning the recently released Grok-4.1. This indicates that in real-world use, people are already preferring its outputs over all other available models.
A Major Leap Forward for AI
The release of Gemini 3 is more than just another update; it’s a clear signal that Google is pushing the boundaries of what’s possible with AI. Its state-of-the-art performance, particularly in complex reasoning and long-horizon agentic tasks, demonstrates a significant step forward. As Gemini 3 and its “Deep Think” counterpart become more widely available, they are poised to enable a new generation of incredibly powerful and capable AI applications.
To learn more about where this technology is heading, check out our articles on the Future of AI & Trends.
For the official details from Google, you can read their announcement on The Keyword blog.