In a dramatic, nail-biting finish that felt like a scene from a sci-fi movie, humanity has prevailed against a top-tier AI… for now. The recent AtCoder World Finals programming contest became an unexpected battleground, pitting a new OpenAI coding model against the world’s finest human programmers. The result was a stunning display of AI’s rapid advancement and a glimpse into the future of software engineering.
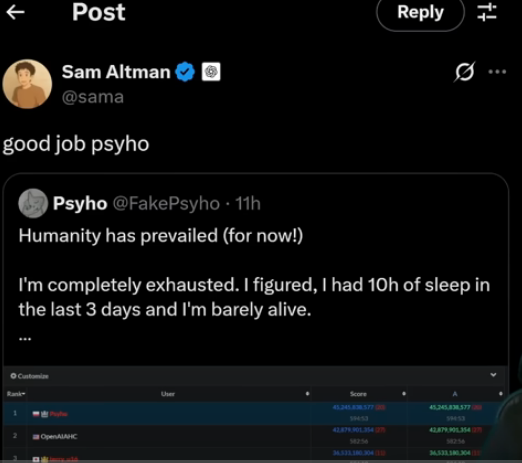
The showdown was so close that it captured the attention of OpenAI’s leadership, with CEO Sam Altman himself tweeting a simple but powerful message to the human victor: “good job psyho.” So, what exactly happened in this man-versus-machine clash, and what does it signal for the future of coding?
Sam Altman, CEO of OpenAI, congratulates the human winner, Psyho.
The AtCoder World Finals: An AI Enters the Arena
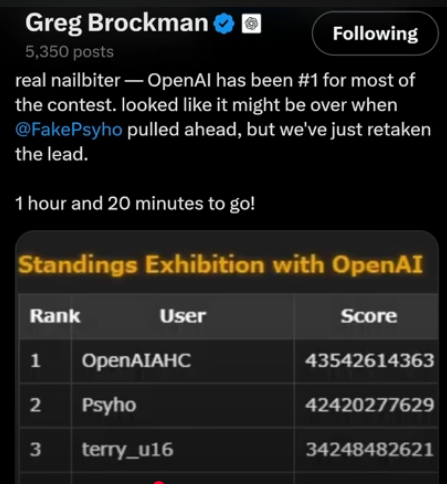
The story began when OpenAI President Greg Brockman announced they were competing in the @atcoder World Finals, a prestigious 10-hour programming contest in Japan. They entered an internal model under the username “OpenAIAHC” (AtCoder Heuristic Contest).
For over nine hours, the AI didn’t just compete; it dominated. The OpenAI coding model held the #1 spot on the leaderboard, systematically outperforming elite human competitors. It looked like a decisive victory for the machine was inevitable.
However, in the final stretch of the grueling 10-hour marathon, a human programmer known as Psyho (@FakePsyho on X) made a heroic comeback. In a stunning turn of events, Psyho, who ironically is a former OpenAI employee who worked on the famous Dota AI, pulled ahead to claim first place. In his victory post, he declared, “Humanity has prevailed (for now!) I’m completely exhausted. I figured, I had 10h of sleep in the last 3 days and I’m barely alive.”
Ahead of Schedule: OpenAI’s Astonishing Progress
This near-victory for the AI is even more significant when placed in the context of OpenAI’s own development timeline. Earlier in the year, Sam Altman had outlined the breathtaking progress of their coding models:
Their 1st reasoning model was ranked around the 1,000,000th best coder in the world.
By September 2024, a model was ranked 9,800th.
By January 2025, their o3 model was ranked 175th.
At that time, an internal model was already the 50th best in the world.
Altman’s projection was that OpenAI would have a “superhuman coder” by the end of 2025. Yet, here we are in mid-2025, and their model came within a hair’s breadth of winning a world championship. This suggests the progress toward a superhuman OpenAI coding model is happening even faster than anticipated.
For most of the 10-hour contest, OpenAI’s model held a commanding lead.
More Than Algorithms: The Significance of a Heuristic Contest
It’s crucial to understand that this wasn’t just a test of raw computation. The AtCoder contest was a Heuristic competition. This involves solving NP-hard optimization problems—complex challenges where there isn’t a simple, perfect algorithmic solution.
Success requires creativity, intuition, and finding “good enough” solutions under tight constraints, much like real-world engineering. This is far more impressive than solving a standard, clear-cut problem.
This event is reminiscent of the 2016 match where Google DeepMind’s AlphaGo defeated Go champion Lee Sedol. A pivotal moment was “Move 37,” an unconventional play by the AI that experts initially dismissed as a mistake. It turned out to be a brilliant, creative move that was key to its victory. Similarly, the OpenAI coding model demonstrated an ability to develop novel strategies that challenged its human counterparts.
Will AI Replace Coders? The Real Takeaway is Enablement
While this news might seem alarming for software engineers, the consensus from experts, including the narrator and even the winner Psyho, points to a different future: enablement, not replacement. This event doesn’t mean human coders are obsolete. Instead, it highlights how AI will become an incredibly powerful tool.
Where AI Wins vs. Where Humans Win
Psyho himself broke down the dynamic:
AI Excels: In standard or “noisy” problems where it can leverage a huge computational budget to explore solutions.
Humans Excel: In “creative” problems that require devising a complex “base” solution from scratch, where human ingenuity and intuition provide the crucial starting point.
The future of software development will likely be a partnership. Great engineers will be enabled by these AI systems to achieve more, faster. They will orchestrate AI agents, guide their problem-solving, and provide the creative spark, while the AI handles the complex, brute-force optimization and exploration.
The market is already voting for this future. The rush to build and acquire AI-assisted IDEs and coding agents—from Cursor to Winsurf to Amazon’s new CodeGlow—shows that the industry is betting on human-in-the-loop collaboration. For more on this trend, check out our latest Future of AI & Trends analysis.
So, while humanity won this round, the race is far from over. This incredible showdown has given us a clear picture of a future where AI and human programmers work together to build the next generation of technology.
The recent joint statement from Microsoft and OpenAI has reaffirmed their long-term AI partnership, as reported by FutureTools News. This commitment to collaboration is expected to drive innovation in the field of artificial intelligence and shape the future of technology. The partnership between Microsoft and OpenAI has been instrumental in developing cutting-edge AI solutions, including the integration of OpenAI’s models with Microsoft’s Azure cloud platform.
Background of the Partnership
The partnership between Microsoft and OpenAI was formed with the goal of advancing the field of artificial intelligence and developing new technologies that can benefit society. The collaboration has led to significant breakthroughs in areas such as natural language processing and computer vision. The joint statement from Microsoft and OpenAI emphasizes their shared commitment to responsible AI development and the importance of ensuring that AI systems are aligned with human values.
Key Areas of Focus
The partnership between Microsoft and OpenAI is focused on several key areas, including the development of large language models and the integration of AI with other technologies such as GitHub and AWS. The goal is to create AI systems that can learn and improve over time, and that can be used to solve complex problems in areas such as healthcare and education. As stated by a Microsoft spokesperson,
The partnership between Microsoft and OpenAI is a key part of our strategy to advance the field of artificial intelligence and to develop new technologies that can benefit society. We are committed to working together to ensure that AI systems are developed and used in ways that are responsible and aligned with human values.
Future Directions
The joint statement from Microsoft and OpenAI also highlights their plans for future collaboration and innovation. The partners are expected to continue working together to develop new AI technologies and to explore new applications for AI in areas such as cybersecurity and sustainability. The partnership is also expected to drive innovation in the field of AI ethics and to promote the development of AI systems that are transparent, explainable, and fair. As the field of artificial intelligence continues to evolve, the partnership between Microsoft and OpenAI is likely to play a significant role in shaping the future of technology and ensuring that AI systems are developed and used in ways that benefit society.
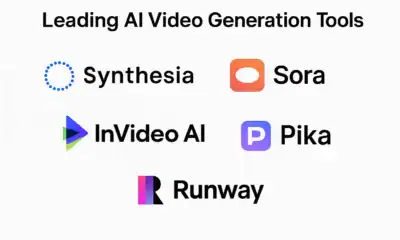
The field of AI image generation has witnessed tremendous growth in recent years, with various models and techniques being developed to create realistic and diverse images. As reported by The Rundown AI, the latest advancements in this field have led to the emergence of a new top banana in AI image generation. This article will delve into the details of this new development and explore its potential applications.
Introduction to AI Image Generation
AI image generation refers to the use of artificial intelligence algorithms to create images that are similar to those produced by humans. This technology has numerous applications, including computer vision, robotics, and gaming. The process of AI image generation involves training a model on a large dataset of images, which enables it to learn patterns and features that can be used to generate new images.
The New Top Banana in AI Image Generation
According to The Rundown AI, the new top banana in AI image generation is a model developed by Anthropic, a leading AI research organization. This model has demonstrated exceptional capabilities in generating high-quality images that are comparable to those produced by humans. The model’s architecture is based on a combination of deep learning and machine learning techniques, which enables it to learn complex patterns and features from large datasets.
The new top banana in AI image generation has the potential to revolutionize the field of computer vision and enable the development of more sophisticated AI-powered applications.
Applications of AI Image Generation
The applications of AI image generation are diverse and widespread. Some of the most significant applications include computer vision, robotics, gaming, and healthcare. In computer vision, AI image generation can be used to create synthetic images that can be used to train models for object detection, segmentation, and recognition. In robotics, AI image generation can be used to create realistic simulations of environments, which can be used to train robots to navigate and interact with their surroundings.
Creating an AI Assistant with its Own Phone Number
In addition to AI image generation, The Rundown AI also provides information on how to create an AI assistant with its own phone number. This can be achieved using a combination of natural language processing and machine learning techniques, which enable the AI assistant to understand and respond to voice commands. The AI assistant can be integrated with various platforms, including GitHub, to enable seamless communication and interaction.
Conclusion
In conclusion, the new top banana in AI image generation has the potential to revolutionize the field of computer vision and enable the development of more sophisticated AI-powered applications. The applications of AI image generation are diverse and widespread, and the technology has the potential to transform various industries, including healthcare, gaming, and robotics. As reported by The Rundown AI, the future of AI image generation looks promising, and we can expect to see significant advancements in this field in the coming years.
The concept of intelligence ownership has been gaining traction in recent years, and for good reason. As Cisco has demonstrated, owning intelligence rather than renting it can be a game-changer for enterprises looking to scale their operations securely. According to a recent article by The Rundown AI, Cisco’s strategy to scale agents securely and reshape enterprise workflows is a prime example of this shift.
The Importance of Intelligence Ownership
Owning intelligence means having control over the data, algorithms, and insights that drive business decisions. This is particularly crucial in today’s fast-paced, data-driven world, where artificial intelligence and machine learning are becoming increasingly prevalent. By owning their intelligence, enterprises can ensure that their systems are secure, transparent, and aligned with their overall goals.
Scaling Agents Securely with Cisco
Cisco’s approach to scaling agents securely is centered around the idea of intelligence ownership. By developing and owning their own AI-powered agents, Cisco is able to ensure that their systems are secure, efficient, and tailored to their specific needs. This approach has allowed Cisco to reshape their enterprise workflows and improve overall productivity. As AWS and other cloud providers continue to evolve, the importance of owning intelligence will only continue to grow.
Cisco’s strategy is a great example of how owning intelligence can help enterprises scale their operations securely and efficiently. By taking control of their data and algorithms, companies can ensure that their systems are aligned with their overall goals and values.
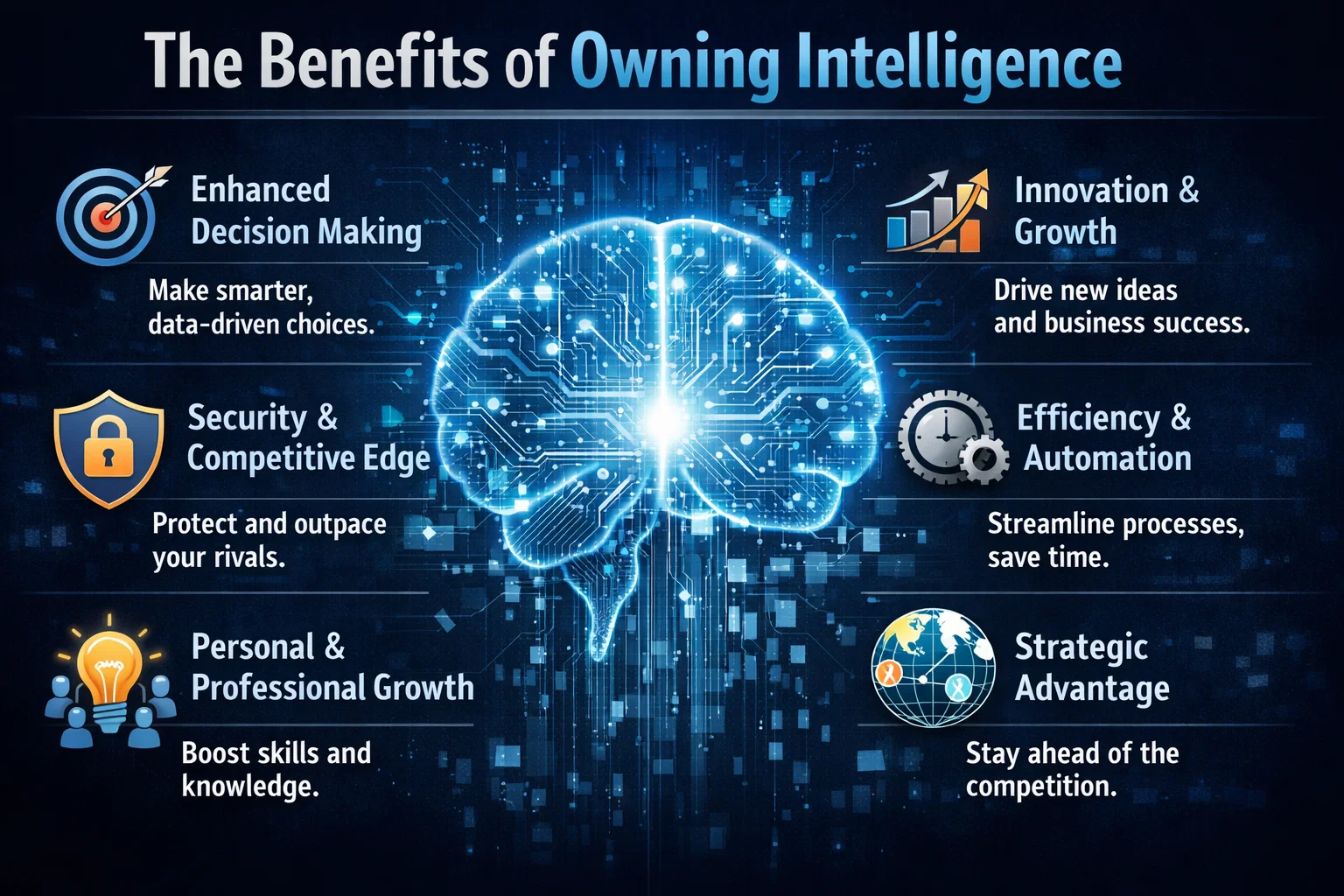
The Benefits of Owning Intelligence
So why should enterprises prioritize intelligence ownership? The benefits are numerous. For one, owning intelligence provides a level of control and transparency that is difficult to achieve with rented intelligence. It also allows enterprises to develop systems that are tailored to their specific needs and goals, rather than relying on generic, off-the-shelf solutions. Additionally, owning intelligence can help enterprises to improve their overall security posture, as they are able to develop and implement their own security protocols and measures.
In contrast, rented intelligence can be limiting and inflexible. When enterprises rely on rented intelligence, they are often at the mercy of the provider, with limited control over the data, algorithms, and insights that drive their business decisions. This can lead to a lack of transparency, security risks, and a general sense of disempowerment.
Real-World Applications
So what does intelligence ownership look like in practice? One example is the development of custom GitHub repositories, which allow enterprises to own and control their code and data. Another example is the use of Azure and other cloud platforms to develop and deploy custom AI-powered solutions. By taking control of their intelligence, enterprises can develop systems that are tailored to their specific needs and goals, and that provide a level of security, transparency, and efficiency that is difficult to achieve with rented intelligence.