Artificial intelligence is evolving at a breathtaking pace, with new breakthroughs and concepts emerging constantly. Keeping up with the jargon can feel like a full-time job, even for those in the tech industry. That’s why understanding the essential AI terms that define the current landscape is more important than ever. This guide breaks down the seven most critical concepts you need to be familiar with, from the autonomous systems changing how we work to the theoretical future of intelligence itself.
[EMBED YOUTUBE VIDEO HERE]
Watch as we break down 7 essential AI terms on our lightboard.
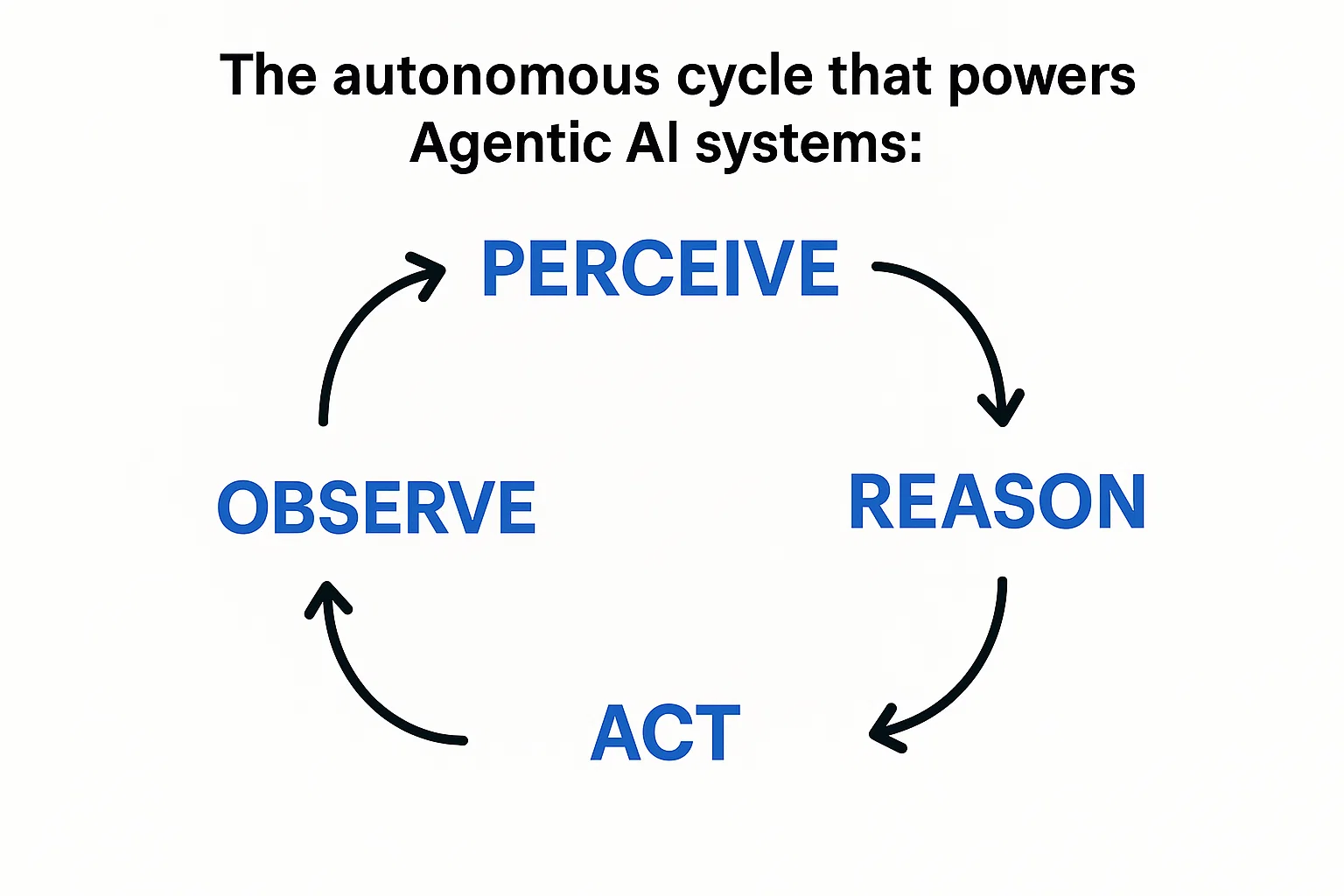
You’ve likely heard of AI agents, as it seems everyone is building the next generation of them. Unlike a simple chatbot that responds to one prompt at a time, Agentic AI refers to systems that can reason, plan, and act autonomously to achieve a specific goal. These agents operate in a continuous loop:
Perceive: They assess their environment and gather information.
Reason: They analyze the information and decide on the best course of action.
Act: They execute the planned steps.
Observe: They monitor the results of their actions and feed that information back into the perception stage to refine their next move.
This allows them to take on complex roles, such as acting as a travel agent to book an entire trip, a data analyst to spot trends in reports, or even a DevOps engineer to detect anomalies in logs and deploy fixes automatically.
The autonomous cycle that powers Agentic AI systems.
2. Large Reasoning Model (LRM)
Agentic AI is powered by a specialized form of large language model (LLM) known as a Large Reasoning Model (LRM). While standard LLMs generate responses almost instantly, LRMs are fine-tuned to work through complex problems step-by-step. They generate an internal “chain of thought” to break down a task before providing a final answer.
This methodical approach is exactly what AI agents need to plan multi-step tasks. LRMs are trained on problems with verifiably correct answers, like math problems or code that can be tested by a compiler. This allows them to learn how to generate logical reasoning sequences that lead to accurate outcomes. When you see a chatbot “thinking…” before it responds, that’s often the LRM at work.
3. Vector Database
To process vast amounts of information, AI needs a specialized way to store it. A Vector Database doesn’t store raw data like text files or images as simple blobs. Instead, it uses an embedding model to convert this unstructured data into numerical representations called vectors.
A vector is essentially a long list of numbers that captures the semantic meaning and context of the original data. By storing data this way, the database can perform incredibly fast and powerful similarity searches. Instead of looking for exact keywords, it looks for vectors that are mathematically close to each other in the “embedding space.” This allows it to find semantically similar content, even if the wording is completely different. For example, a search using an image of a mountain vista can find other photos of mountains, even with different compositions.
4. RAG (Retrieval-Augmented Generation)
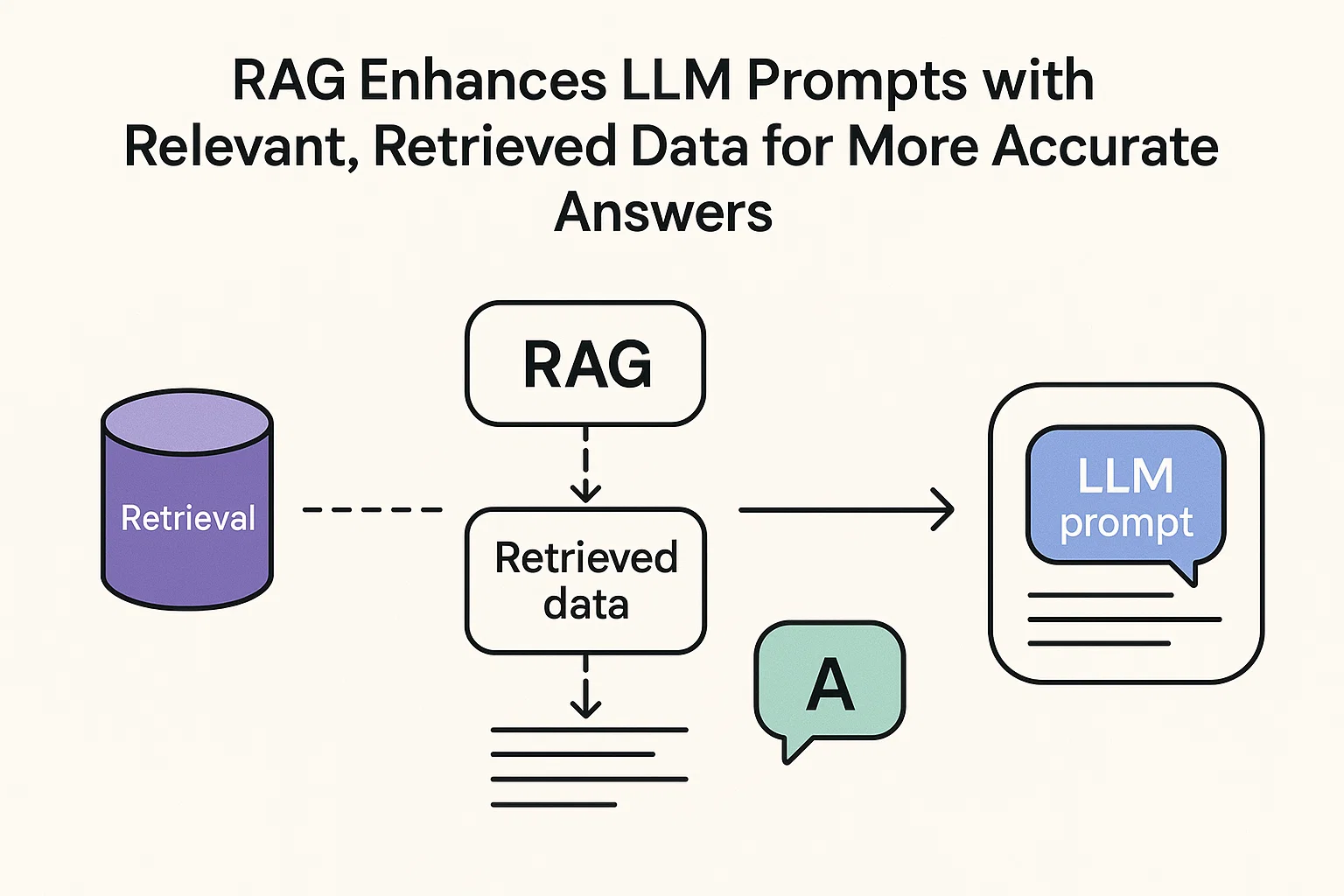
Retrieval-Augmented Generation (RAG) is a powerful technique that leverages vector databases to make LLMs more accurate and context-aware. It prevents models from “hallucinating” or making up facts by grounding them in real-world data. The process works like this:
A user submits a prompt (e.g., a question about company policy).
The RAG system’s retriever uses an embedding model to convert the prompt into a vector.
It searches a vector database (containing, for example, the company’s employee handbook) to find the most semantically relevant information.
This retrieved information is then added to the original prompt as extra context.
This “augmented” prompt is sent to the LLM, which can now generate a much more accurate and informed response based on the provided data.
RAG enhances LLM prompts with relevant, retrieved data for more accurate answers.
5. MCP (Model Context Protocol)
For LLMs to be truly useful, they need to interact with external data sources, tools, and services like databases, code repositories, or email servers. The Model Context Protocol (MCP) is an emerging standard designed to streamline these interactions.
Instead of developers building custom, one-off connections for every tool, MCP provides a standardized framework. An MCP Server acts as a universal adapter, allowing an LLM to seamlessly connect to any MCP-compliant tool or data source. This makes integrating AI with existing systems much simpler and more scalable.
6. MoE (Mixture of Experts)
Mixture of Experts (MoE) is an innovative LLM architecture that makes models more efficient without sacrificing power. Instead of a single, monolithic model, an MoE model is composed of numerous smaller, specialized neural subnetworks called “experts.”
When a prompt is received, a “routing mechanism” intelligently activates only the most relevant experts needed for that specific task. While the model may have billions of total parameters across all its experts, it only uses a fraction of those “active parameters” for any given inference. This approach allows for the creation of massive, highly capable models that are significantly faster and less computationally expensive to run than traditional dense models of a similar size.
7. ASI (Artificial Super Intelligence)
Finally, we arrive at the frontier of AI theory. You may have heard of Artificial General Intelligence (AGI), a hypothetical AI that can perform any intellectual task a human expert can. However, the ultimate goal for many frontier AI labs is Artificial Super Intelligence (ASI).
ASI is a purely theoretical concept at this point. It describes an AI with an intellectual scope that dramatically exceeds the cognitive performance of the brightest human minds in virtually every field. A key theoretical trait of an ASI would be its capacity for recursive self-improvement—the ability to redesign and upgrade itself in an endless cycle, becoming exponentially smarter. While we don’t know if ASI is achievable, it remains one of the most profound and essential AI terms shaping the long-term vision of the field. For more on this, you might explore articles on the future of AI and its trends.
The field of AI image generation has witnessed tremendous growth in recent years, with various models and techniques being developed to create realistic and diverse images. As reported by The Rundown AI, the latest advancements in this field have led to the emergence of a new top banana in AI image generation. This article will delve into the details of this new development and explore its potential applications.
Introduction to AI Image Generation
AI image generation refers to the use of artificial intelligence algorithms to create images that are similar to those produced by humans. This technology has numerous applications, including computer vision, robotics, and gaming. The process of AI image generation involves training a model on a large dataset of images, which enables it to learn patterns and features that can be used to generate new images.
The New Top Banana in AI Image Generation
According to The Rundown AI, the new top banana in AI image generation is a model developed by Anthropic, a leading AI research organization. This model has demonstrated exceptional capabilities in generating high-quality images that are comparable to those produced by humans. The model’s architecture is based on a combination of deep learning and machine learning techniques, which enables it to learn complex patterns and features from large datasets.
The new top banana in AI image generation has the potential to revolutionize the field of computer vision and enable the development of more sophisticated AI-powered applications.
Applications of AI Image Generation
The applications of AI image generation are diverse and widespread. Some of the most significant applications include computer vision, robotics, gaming, and healthcare. In computer vision, AI image generation can be used to create synthetic images that can be used to train models for object detection, segmentation, and recognition. In robotics, AI image generation can be used to create realistic simulations of environments, which can be used to train robots to navigate and interact with their surroundings.
Creating an AI Assistant with its Own Phone Number
In addition to AI image generation, The Rundown AI also provides information on how to create an AI assistant with its own phone number. This can be achieved using a combination of natural language processing and machine learning techniques, which enable the AI assistant to understand and respond to voice commands. The AI assistant can be integrated with various platforms, including GitHub, to enable seamless communication and interaction.
Conclusion
In conclusion, the new top banana in AI image generation has the potential to revolutionize the field of computer vision and enable the development of more sophisticated AI-powered applications. The applications of AI image generation are diverse and widespread, and the technology has the potential to transform various industries, including healthcare, gaming, and robotics. As reported by The Rundown AI, the future of AI image generation looks promising, and we can expect to see significant advancements in this field in the coming years.
The recent launch of the Cursor plugin marketplace is a significant development in the field of artificial intelligence, enabling users to extend the capabilities of AI agents with external tools. As reported by FutureTools News, this innovative platform is set to transform the way AI agents are used in various industries. The plugin marketplace is designed to provide users with a wide range of tools and services that can be seamlessly integrated with AI agents, enhancing their functionality and performance.
Introduction to Cursor Plugin Marketplace
The Cursor plugin marketplace is an online platform that allows developers to create, share, and deploy plugins for AI agents. These plugins can be used to add new features, improve existing ones, or even create entirely new applications. With the launch of this marketplace, Cursor is providing a unique opportunity for developers to showcase their skills and creativity, while also contributing to the growth of the AI ecosystem. As mentioned on the Cursor blog, the plugin marketplace is an essential component of the company’s strategy to make AI more accessible and user-friendly.
Benefits of the Plugin Marketplace
The Cursor plugin marketplace offers several benefits to users, including the ability to extend the capabilities of AI agents, improve their performance and efficiency, and enhance their overall user experience. By providing access to a wide range of plugins, the marketplace enables users to tailor their AI agents to meet specific needs and requirements. This can be particularly useful in industries such as customer service, healthcare, and finance, where AI agents are increasingly being used to automate tasks and improve decision-making. As noted by experts in the field, the use of machine learning and natural language processing can significantly enhance the capabilities of AI agents.
Key Features of the Plugin Marketplace
The Cursor plugin marketplace features a user-friendly interface, making it easy for developers to create, deploy, and manage plugins. The platform also provides a range of tools and services, including APIs, SDKs, and documentation, to support plugin development. Additionally, the marketplace includes a review and rating system, allowing users to evaluate and compare plugins based on their quality, functionality, and performance. As stated by the GitHub community, the use of open-source plugins can significantly accelerate the development of AI applications.
The launch of the Cursor plugin marketplace is a significant milestone in the development of AI agents, and we are excited to see the innovative plugins that will be created by our community of developers. – Cursor Team
Future of AI Agents and Plugin Marketplaces
The launch of the Cursor plugin marketplace is a clear indication of the growing importance of AI agents and plugin marketplaces in the technology industry. As AI continues to evolve and improve, we can expect to see more innovative applications and use cases emerge. The use of cognitive services and conversational AI can significantly enhance the capabilities of AI agents, enabling them to interact more effectively with humans and perform complex tasks. As reported by FutureTools News, the future of AI agents and plugin marketplaces looks promising, with significant opportunities for growth and innovation.
In the ever-evolving world of artificial intelligence, efficiency is king. While major announcements often come with fanfare, some of the most groundbreaking innovations arrive quietly. The latest “DeepSeek moment” is a perfect example, introducing a technology that could fundamentally change how we feed information to large language models. This new frontier is called DeepSeek OCR, and it’s a powerful exploration into optical context compression that has massive implications for the future of AI.
The vLLM project announced support for the new DeepSeek OCR model.
What is DeepSeek OCR and How Does it Work?
At its core, DeepSeek OCR (Optical Character Recognition) is a new method for compressing visual information for LLMs. Instead of feeding a model pages and pages of text (which consumes a lot of tokens), this technology converts that text into an image. The model then processes this single image, which contains all the original information but in a highly compressed format.
The implications are staggering. According to the vLLM project, this method allows for blazing-fast performance, running at approximately 2500 tokens/s on an A100-40G GPU. It can compress visual contexts up to 20x while maintaining an impressive 97% OCR accuracy.
Unpacking the Performance Gains
A performance chart for the OmniDocBench benchmark tells a compelling story. The chart plots “Overall Performance” against the “Average Vision Tokens per Image.”
Fewer Tokens, Better Performance: As you move to the right on the chart, the number of vision tokens used to represent an image decreases. As you move up, the overall performance gets better.
DeepSeek’s Dominance: The various DeepSeek OCR models (represented by red dots) form the highest curve on the graph. This demonstrates they achieve the best performance while using significantly fewer vision tokens compared to other models like GOT-OCR2.0 and MinerU2.0.
Essentially, DeepSeek has found a way to represent complex information more efficiently, which is a critical step in overcoming some of AI’s biggest hurdles.
For more on how AI models are benchmarked, check out our articles in the AI Technology Explained category.
An image can convey complex ideas far more efficiently than lengthy text.
Why Image-Based Compression is a Game-Changer
Think of it like a meme. Using a single image, like the popular Drake format, we can convey a lot of information—emotion, cultural context, humor—that would otherwise take many paragraphs of text to explain. An image acts as a dense packet of information.
This is exactly what DeepSeek OCR is proving. We can take a large amount of text, which would normally consume thousands of tokens, render it as an image, and feed that single image to a Vision Language Model (VLM). The result is a massive compression of data without a significant loss of meaning or “resolution.”
Solving Core AI Bottlenecks
This efficiency directly addresses several major bottlenecks slowing down AI progress:
Memory & Context Windows: AI models have a limited “memory” or context window. As you feed them more and more information (tokens), they start to forget earlier parts of the conversation. By compressing huge amounts of text into a single image, we can effectively expand what fits into this window, allowing models to work on larger projects and codebases without performance degradation.
Training Speed & Cost: Training AI models is incredibly expensive and time-consuming, partly due to the sheer volume of data they need to process. By compressing the training data, models can be trained much faster and cheaper. This is especially crucial for research labs that may not have access to the same level of GPU resources as major US companies.
Scaling Laws: Increasing a model’s context window traditionally comes at a quadratic increase in computational cost. This new visual compression method offers a way to bypass that limitation, potentially leading to more powerful and efficient models.
Expert Insight: Andrej Karpathy on Pixels vs. Text
The significance of this paper wasn’t lost on AI expert Andrej Karpathy. In a post on X, he noted that the most interesting part of the DeepSeek OCR paper is the fundamental question it raises: “whether pixels are better inputs to LLMs than text.”
Karpathy suggests that text tokens might be “wasteful and just terrible” at the input stage. His argument is that all inputs to LLMs should perhaps only ever be images. Even if you have pure text, it might be more efficient to render it as an image first and then feed that into the model.
This approach offers several advantages:
More Information Compression: Leads to shorter context windows and greater efficiency.
More General Information Stream: An image can include not just text, but bold text, colored text, and other visual cues that are lost in plain text.
More Powerful Processing: Input can be processed with bidirectional attention by default, which is more powerful than the autoregressive method used for text.
Karpathy concludes that this paradigm shift means “the tokenizer must go,” referring to the clunky process of breaking words into tokens, which often loses context and introduces inefficiencies.
The work on DeepSeek OCR provides more than just a faster way to process documents; it offers a blueprint for a new kind of biological and informational discovery. By leveraging visual modality as an efficient compression medium, we open up new possibilities for rethinking how vision and language can be combined. This could dramatically enhance computational efficiency in large-scale text processing and agent systems, accelerating everything from financial analysis to the discovery of new cancer therapies. The future of AI might just be more visual than we ever imagined.